
Making Better Decisions with Offline Deep Reinforcement Learning
Introduction:
In the age of big data, we have massive amounts of data available at our disposal and it would nice if we could use some of that to make better decisions in the future. For example in healthcare we are interested in data-drive decision making by developing decision-support systems for clinicians. Such systems take EHRs and real-time data about patient’s physiological information and can recommend treatment (medication types and dosages) and insights to clinicians. The goal here is improve the overall careflow and eventual mortality outcome if the disease is severe.
How might the past have changed if different decisions were made? This question has captured the fascination of people for hundreds of years. By precisely asking, and answering such questions of counterfactual inference, we have the opportunity to both understand the impact of past decisions (has climate change worsened economic inequality?) and inform future choices (can we use historical electronic medical records data about decision made and outcomes, to create better protocols to enhance patient health?). - Emma Brunskill
In this post we discuss some common quantitative approaches to counterfactual reasoning, as well as a few problems and questions that can be addressed through the lens of counterfactual reasoning, including healthcare.
The reinforcement learning (RL) provides a good framework to approach problems of these kind. However, most techniques in RL assume we have an agent that is continually interacting with the world and receiving a reward at each time step. Making use of historically logged data is an interesting problem in RL which has been receiving much attention is recent times. This problem is also important because policies can have real-world impact and some guarantees on their performance prior to deployment is quite desirable. For example in case of healthcare, learning a newly treatment policy and directly executing it would be risky.
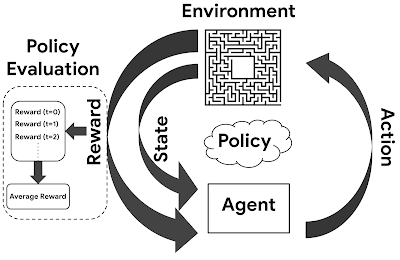
One of the problems we face in offline RL is that of evaluating the performance of newly learned policies. i.e we want to estimate the expected reward of a target policy(sometimes known as evaluation policy) and we are given a data log generated by the behaviour policy. Hence we would like to get a reliable estimate without actually executing the policy. Without this capability we would need to launch a number of A/B tests to search for the optimal model and hyperparameters[1].
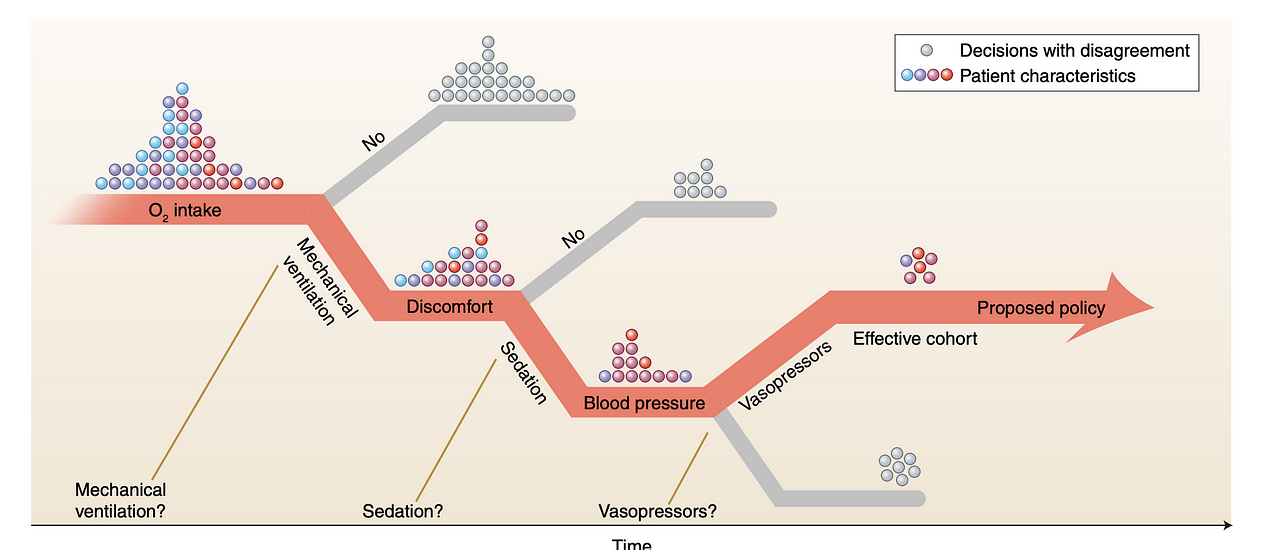
The more decisions that are performed in sequence, the likelier it is that a new policy disagrees with the one that was learned from
This problem is hard because of the mismatch between data distributions. Taking the healthcare example again, Intuitively this means we want to find scenarios where decisions made(actions taken) by the physicians match or nearly match the learned policy. Here We estimate the reward based on the actual outcomes of the treatments that happened in the past. But what makes it challenging is the fact that for a new policy where is no similar history available where we have the actual outcome available for comparison.
Decision Modeling:
In offline RL our goal is to find the best policy possible given the available data.
Offline reinforcement learning can be seen as a variant of standard off policy RL algorithms and usually tend to optimize some form of a Bellman equation or TD difference error[6]. The goal is take the given data and generalize and perform well on future unseen data. This is similar to supervised learning but here the exact answer is not known rather we have data trajectories and some reward signal. If the available These offline- RL algorithms can be surprisingly powerful in terms of exploiting the data to learn a general policy (see Work done by Agarwal et al.). The diversity of data cannot be emphasised enough(which means it is better to use data from many different policies rather than one fixed policy.)
Many Standard libraries have popped up making the process of modeling quite accessible for average Engineers. For example intel coach offers implementations of many state of the art Deep RL algorithms.
Counterfactual policy evaluation:
OPE is the problem of estimating the value of a target policy using only pre-collected historical data generated by another policy. Formally:
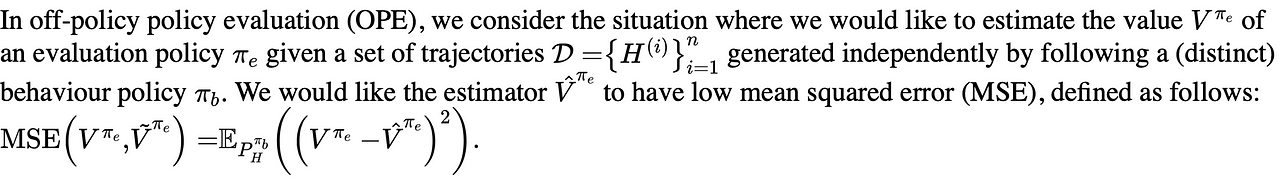

Several well known counterfactual policy evaluation (CPE) methods exist.
we evaluate the quality of Off Policy estimator by evaluating its mean squared error (MSE). Mean square error which is defined as the Difference between Estimate of the Evaluation policy and true Evaluation Policy value. Smaller the error the better the estimator.
These methods can be roughly divided into three classes: importance sampling (IS) methods and doubly robust and hybrid[3]. Each have their own pros and cons in terms of bias and variance trade-off. And there are techniques which have been proposed which try combine the best of both world. Following estimators have proven to be useful in a variety of domains:
- Step-wise importance sampling estimator
- Step-wise direct sampling estimator
- Step-wise doubly-robust estimator (Dudık et al., 2011)
- Sequential doubly-robust estimator (Jiang & Li, 2016)
- MAGIC estimator (Thomas & Brunskill, 2016)
Model Selection using OPE: When training models its more useful to evaluate the policy rather than judging the training performance by looking at the scores. Policy describes the actions that model choses and we pick some estimator like for example the MAGIC estimator to evaluate the performance of the newly trained policy. One simple way of choosing between the various trained models is pick one with smallest mean square error estimate[2].

A good estimator returns an accurate estimate by requiring less data compared to sub-optimal one.
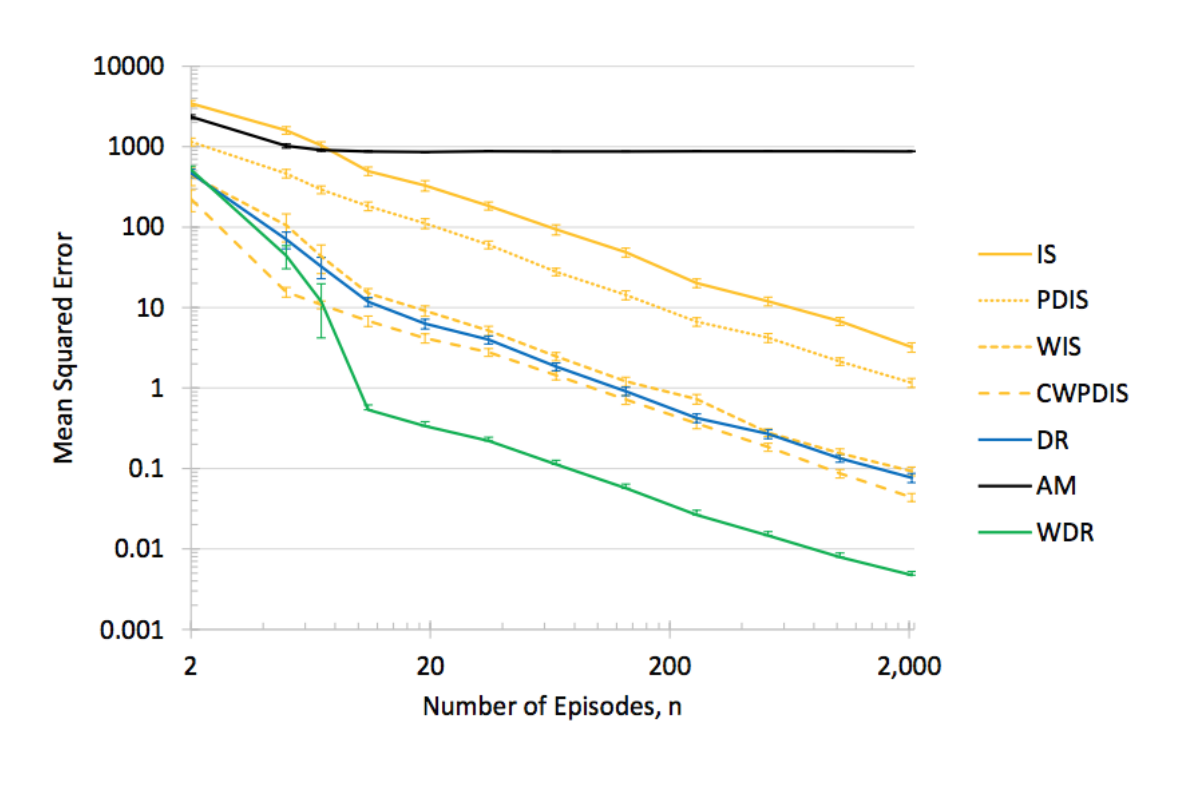
Lastly, We should keep in mind that there is no single estimator method that performs well for all application domains. Voloshin et al. [3] offer guidelines for selecting the appropriate OPE for a given application(see figure below). They have conducted a comprehensive Empirical Study to benchmark various OPEs in a variety of environments.
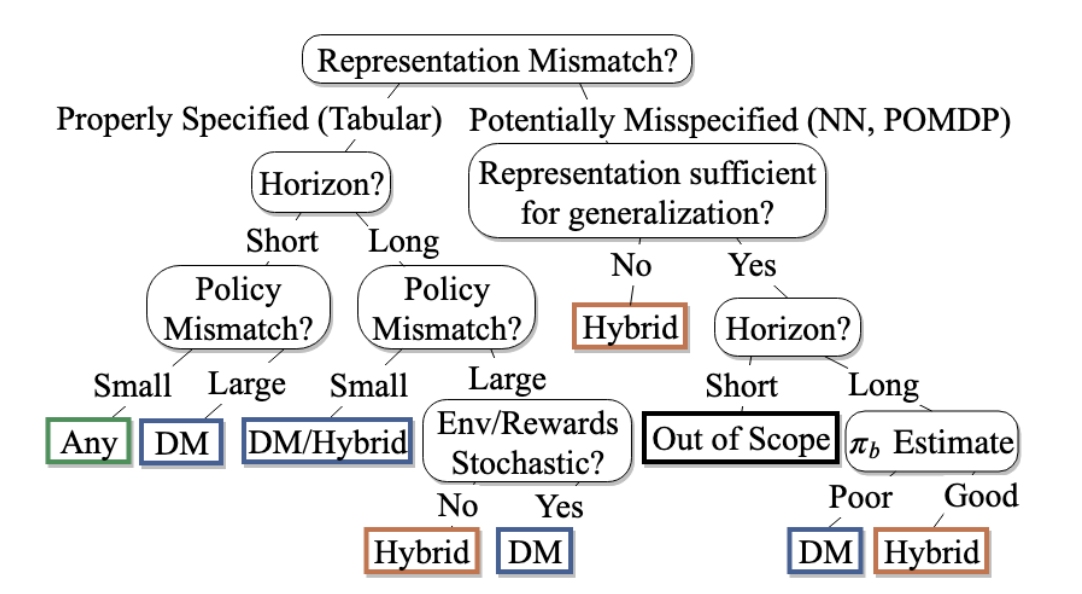
read more:
- Sutton, R. S. & Barto, A. G. Reinforcement Learning: An Introduction. Chapter 5.5.
- http://tgabel.de/cms/fileadmin/user_upload/documents/Lange_Gabel_EtAl_RL-Book-12.pdf
- https://people.cs.umass.edu/~pthomas/papers/Thomas2015c.pdf
- Survey paper of batch RL to write prev section https://arxiv.org/pdf/2005.01643.pdf
- IS: https://medium.com/@jonathan_hui/rl-importance-sampling-ebfb28b4a8c6
- additional resource: https://danieltakeshi.github.io/2020/06/28/offline-rl/
— -
References:
[2] https://people.cs.umass.edu/~pthomas/papers/Yao2017.pdf
[3] https://arxiv.org/pdf/1911.06854.pdf
[4] https://ai.googleblog.com/2019/06/off-policy-classification-new.html
[5] https://web.stanford.edu/class/cs234/CS234Win2019/slides/lecture15.pdf
[6] https://danieltakeshi.github.io/2020/06/28/offline-rl/
[7] Agarwal, R., Schuurmans, D. & Norouzi, M.. (2020). An Optimistic Perspective on Offline Reinforcement Learning International Conference on Machine Learning (ICML).