
Data is tricky to manage once the operations scale. It can grow exponentially, coming in from new sources, and becoming more diverse, which makes it increasingly challenging to process and find insights. Mature organizations like Google, Airbnb and Uber have a well-established data culture. Some of the lessons we can draw from such mature organizations, in terms of establishing best practice are as follows:
- Data should be treated as code. i.e, creation, deprecation, and critical changes to data artifacts should go through the review process with appropriate written documents where stakeholder's views are taken into account.
- Each data artifact should have a clear owner, and a clear purpose and should be deprecated when its utility is over.
- Data artifacts have tests associated with them and are continuously tested.
- Considering the full end-to-end flow of data across people and systems — can lead to higher overall data quality.
- Teams should aim to be staffed as full-stack' so the necessary data engineering talent is available to take a long view of the data’s whole life cycle. While there are complicated datasets that can be owned by more central teams, most teams that produce data should aim toward local ownership.
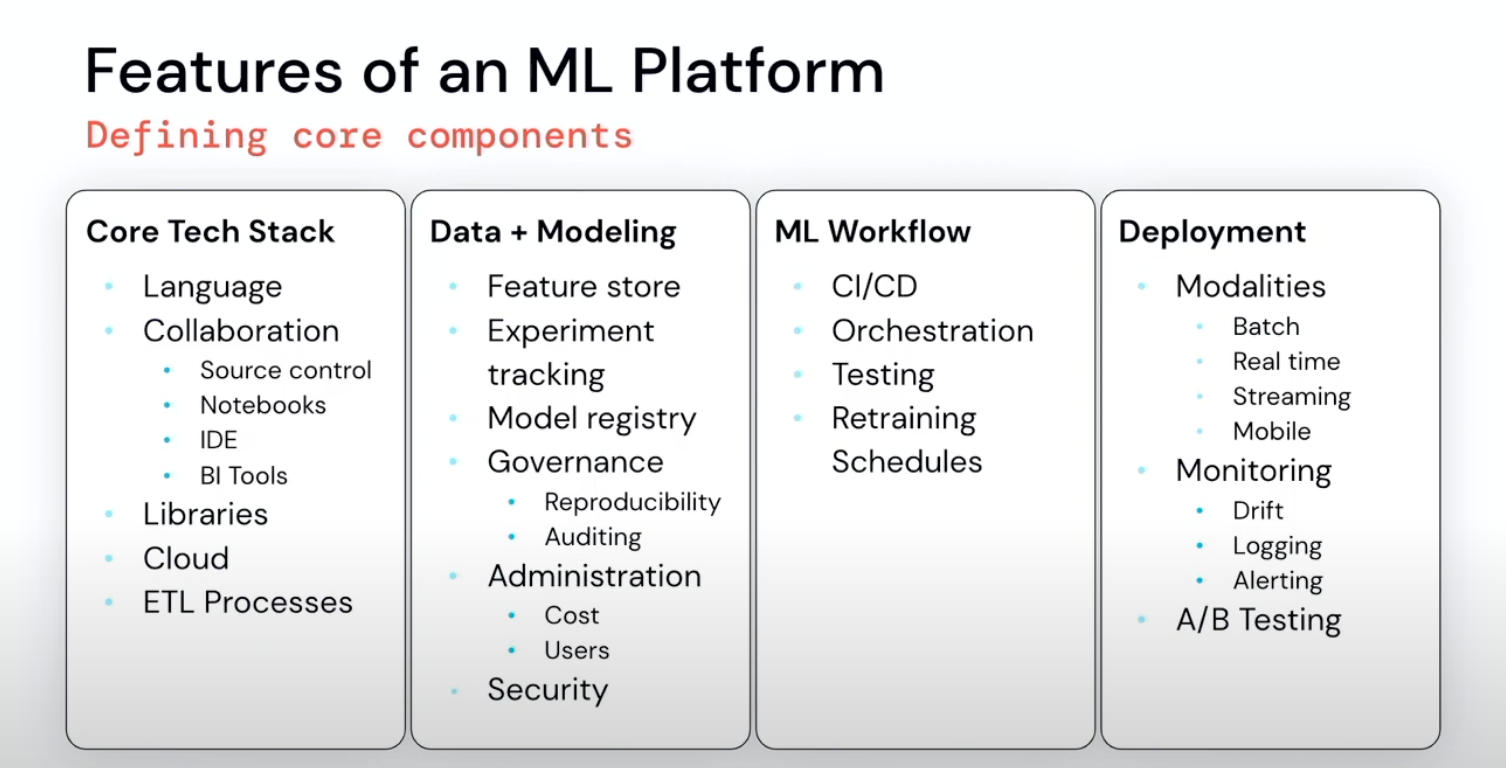
Let's Consider Machine Learning as our primary use-case for building the data platform. Following are some of the key stages for implementing an ML based solution:
Once the initial protoyping and experiments are completed we need to
Enterprise grade ML, a term mentioned in a paper put forth by Microsoft, refers to ML applications where there is a high level of scrutiny for data handling, model fairness, user privacy, and debuggability. While toy problems that data scientists solve on laptops using a CSV dataset could be intellectually challenging, they are not enterprise-grade machine-learning problems.
Deploying ML models requires major manual oversight. We need to ensure:
- Models have been optimized with the right balance between complexity and accuracy.
- Data Pipelines are robust with the required level of monitoring.
- The right level of data and concept drift monitoring is implemented for model re-training.
- In deployment (via containers or spark applications, for example), governance becomes paramount, especially in regulated environments. Data lineage, data versioning, model versioning, model explainability, model monitoring are all front and center.
An end-to-end MLOps process involves establishing the feature engineering pipeline, including the data ingestion to the feature store; the experimentation; and the automated ML workflow pipeline up to the model serving. The pipeline enables Experiment tracking, Model registry, CI/CD and Orchestration workflow and finally model deployment
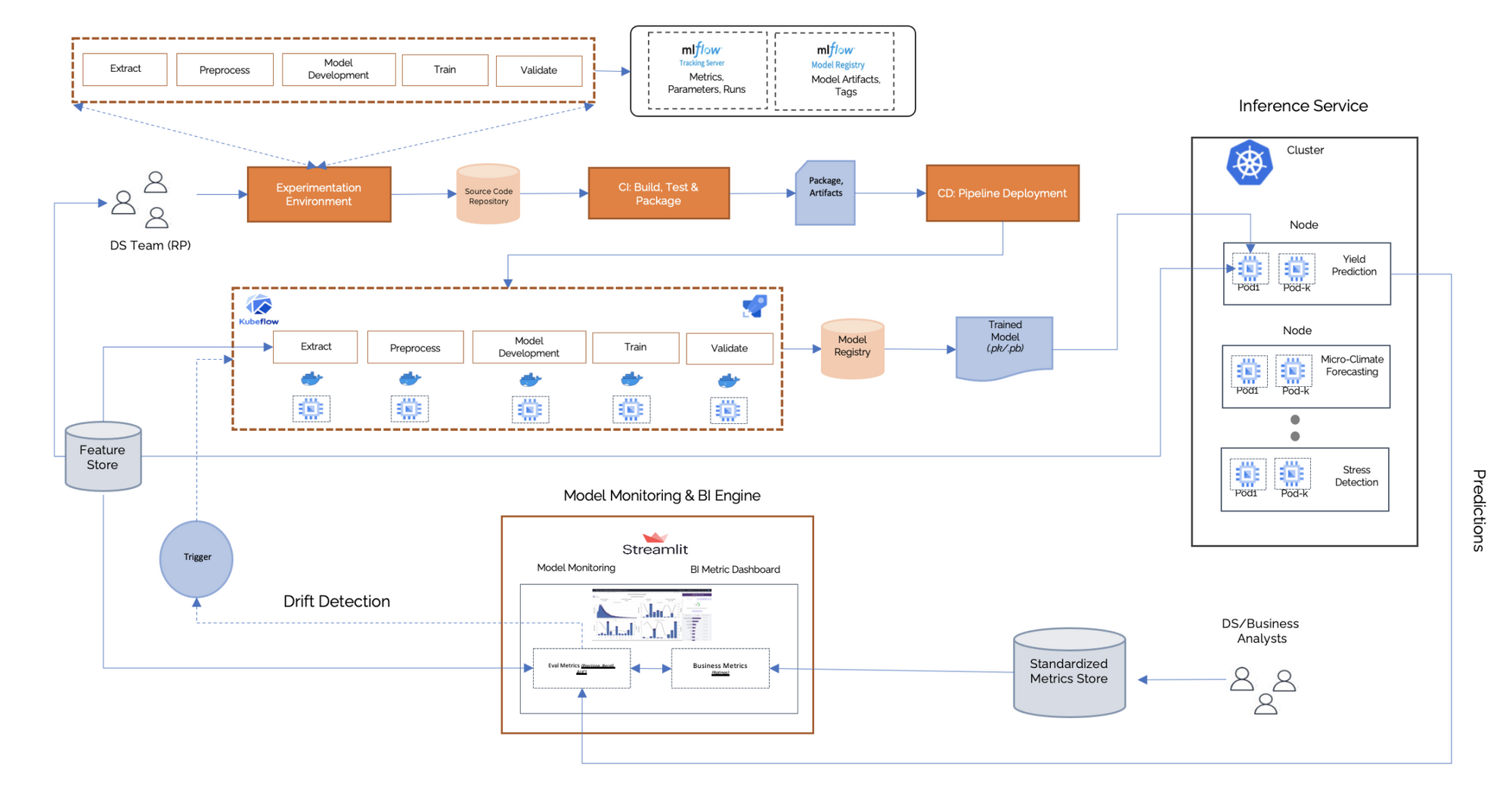
An end-to-end MLOps process involves establishing the feature engineering pipeline, including the data ingestion to the feature store; the experimentation; and the automated ML workflow pipeline up to the model serving. The pipeline Architecture in figure above enables Experiment tracking, Model registry, CI/CD and Orchestration workflow and finally, model deployment.
Feature Store: A data ingestion job loads batch data into the feature store system. A feature store system ensures central storage of commonly used features. It has two databases configured: One database as an offline feature store to serve features with normal latency for experimentation and one database as an online store to serve features with low latency for predictions in production.
Workflow for Experiment Tracking: This is a typical data science process, which is performed at the beginning of implementing ML solution. This level has an experimental and iterative nature. Every step in each pipeline, such as data preparation and validation, model training and testing, is executed manually. The common way to process is to use Rapid Application Development (RAD) tools, such as Jupyter Notebooks. The data scientist estimates the best-performing algorithm and hyperparameters, and the model training is then triggered with the training data. In ML development, multiple experiments on model training can be executed in parallel before making the decision on what model will be promoted to production.
Data Prep: The preparation and validation of the data coming from the feature store system is required. The data preprocessing begins with data transformation and cleaning tasks. The data engineer/scientist defines the data transformation rules (normalization, aggregations) and cleaning rules to bring the data into a usable format. i.e The transformation rule artifact defined in the requirement gathering stage serves as input for this task. These transformation rules are continuously improved based on feedback. Workflow orchestration coordinates the tasks of an ML workflow pipeline according to directed acyclic graphs (DAGs).
Model Registry: The model registry stores centrally the trained ML models together with their metadata. It has two main functionalities: storing the ML artifact and storing the ML metadata
MLFlow Tracking: The development of a workflow happens through many iterations. Multiple variants of the project may be tested concurrently, developed by a team of data scientists working simultaneously. Metadata is tracked and logged for each orchestrated ML workflow task. Metadata tracking and logging is required for each training job iteration (e.g., training date and time, duration, etc.), including the model-specific metadata—e.g., used parameters and the resulting performance metrics, model lineage: data and code used—to ensure the full traceability of experiment runs. Data Scientist will build models and log them to MLflow, which records environment info. “ML assets” as ML model, its parameters and hyperparameters, training scripts, training and testing data. We aim at recording the the identity, components, versioning, and dependencies of these ML artifacts.
CI/CD pipeline automation. Data Scientists move models to Staging where we introduce a CI/CD system to perform fast and reliable ML model deployments in production. The core difference from the previous experimental step is that we now automatically build, test, and deploy the ML Model, and the ML training pipeline components.
Model Serving: The model serving component can be configured for different purposes. Examples are online inference for real-time predictions or batch inference for predictions using large volumes of input data. The serving can be provided, e.g., via a REST API. As a foundational infrastructure layer, a scalable and distributed model serving infrastructure is recommended. Will likely require Azure kubernetes service.
Monitoring: The monitoring component takes care of the continuous monitoring of the model serving performance (e.g., prediction accuracy). Models may degrade over time. We check for concept drift and whenever performance degrades, new data is available, the process of model retraining is triggered. This level of automation also includes data and model validation steps.
References and Further reading
- MLOPS: https://outerbounds.com/docs/infra-stack
https://ml-ops.org/content/mlops-principles
https://arxiv.org/pdf/2205.02302.pdf
-https://www.youtube.com/watch?v=tuIR1Jz2P8k&ab_channel=Databricks - Building a Data Integration Team: Skills, Requirements, and Solutions for Designing Integrations
- 30-day error rates for data-related issues in Google's TFX model serving system [Breck et al., SysML 2019]
- Hidden Technical Debt in Machine Learning Systems
- Harnessing Organizational Knowledge for Machine Learning
- The Chief data Management officer handbook