
“Overall, machine learning systems can be thought of as a machine learning core — usually an advanced algorithm which requires a few chapters from Ian’s book to understand — surrounded by a huge amount of software engineering. The engineering can be shuffling around data, providing wrappers around inputs and outputs, or scheduling distributed code, all of which interface with the core as a black box. A machine learning advance happens when engineering effort plus research effort exceeds some threshold. Each incremental bit of engineering effort (such as decreasing Universe latencies) makes problems incrementally easier for our models, and has a chance to push the research over the finish line.” - source: https://blog.gregbrockman.com/define-cto-openai
Data Engineer is someone who Develops, constructs, tests and maintains infrastructure such as databases and large scale data processing systems. Historically Data Engineer would be required to master a whole suite of toolkit to do fundamental tasks like: Query Data, Process/transform data, assist data scientists to build large-scale models and serve the models standalone or as a product feature. But that has changed in recent times. One of the best general purpose tools out there for large-scale data processing is Apache Spark. It was created to replace hadoop and claims to offer much better performance than its predecessor. It supports major languages, like java, python, R and Scala.
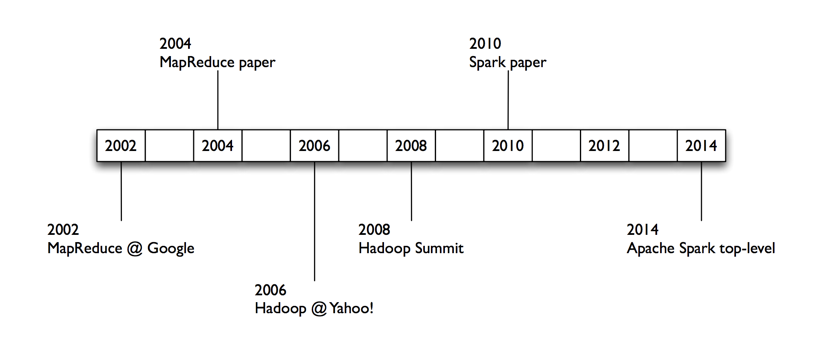
Spark contains multiple closely integrated components. At its core, Spark is a “computational engine” that is responsible for scheduling, distributing, and monitoring applications. The core engine of Spark is both fast and general-purpose, it powers multiple higher-level components specialized for various workloads, such as SQL queries or training machine learning models at scale.
A quick way to learn Spark is to install it locally. We can install it using Vagrant using the following steps.
Download and Install Vagrant
https://www.vagrantup.com/downloads.html
Download and Install Virtual Box https://www.virtualbox.org/wiki/Downloads
Clone this repo: https://github.com/cs109/2015lab8/Inside the repo you should see a file called Vagrantfile.
type $ vagrant up Note: When you run this command for the first time, Vagrant will install Anaconda, Java Development Kit, and Apache Spark. This process may take up to 25 minutes. In subsequent runs, it should take less than a minute…
reload by typing: $vagrant reload
Open your web browser and type in the url: http://localhost:4545/treeOpen up 2015lab8/ folder
When finished, inside 2015lab8/, type $ vagrant halt
Available Data Abstractions
If we go through the documentation we learn that spark offers the following
- RDD (Resilient Distributed Dataset): The main approach to work with unstructured data. Pretty similar to a distributed collection that is not always typed.
- Datasets: The main approach to work with semi-structured and structured data. Typed distributed collection, type-safety at a compile time, strong typing, lambda functions.
- DataFrames: It is the Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. Think about it as a table in a relational database.
Lets look at RDDS which are Spark’s main programming abstraction.
Resilient Distributed Datasets
RDDs represent a collection of items distributed across many compute nodes that can be manipulated in parallel
In Spark all work is expressed as either creating new RDDs, transforming existing RDDs, or calling operations on RDDs to compute a result. Under the hood, Spark automatically distributes the data contained in RDDs across your cluster and parallelizes the operations you perform on them[1] .
Resilient Distributed Datasets (RDD) represent a fault-tolerant collection of elements that can be operated on in parallel two types of operations on RDDs: transformations and actions.
Transformations construct a new RDD from a previous one.
Transformations:
Transformations return another RDD are not really performed until an action is called (lazy). Examples of transformations include map,filter, group by and join operations transformations are lazy (not computed immediately)
- .map( f ) – returns a new RDD applying f to each element •
- .filter( f ) – returns a new RDD containing elements that satisfy f
- .flatmap(f) – returns a ‘flattened’ list
Actions:
return a value other than an RDD are performed immediately
- .reduce( f ) – returns a value reducing RDD elements with f
- .take( n ) – returns n items from the RDD
- .collect() – returns all elements as a list
- .sum() - sum of (numeric) elements of an RDD
Map function: (Think for loop replacement)
a = [1,2,3]
def add1(x):
return x+1
map(add1,a) => [2,3,4]
(apply add1 to the dataset, original list remains untouched)
Filter function(Think WHERE clause in SQL)
a = [1,2,3,4]
def isOdd(x):return x%2==1
filter(isOdd,a) => [1,3]Reduce Function(Think aggregation function like COUNT in SQL)
a = [1,2,3,4]
def add1(x,y): return x+y
reduce(add,a) => [1,2,3,4]The transformed RDD gets recomputed when an action is run on it (default) however, an RDD can be persisted into storage in memory or disk. Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program).
Specifically, to run on a cluster, the SparkContext can connect to several types of cluster managers (either Spark’s own standalone cluster manager, Mesos or YARN), which allocate resources across applications.
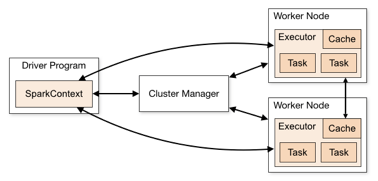
Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application.
Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors.
Finally, SparkContext sends tasks to the executors to run.
Conclusion: Working with data is cool and Data Engineers are quietly working along side data scientists to handle data related problems…
[1] https://learning.oreilly.com/library/view/learning-spark/9781449359034/ch03.html