
In the past decade or so, businesses have realized that they can extract value out of the data they collect (e.g. user data and event data) to make data-informed decisions that replace the old model of deciding best argument with gut instinct, loudest voice, and so on.
Data science is the study and practice of extracting insights and knowledge from large amounts of data. The insights gathered through this approach can for example help improve the efficiency of existing processes and lower operational costs. Data-driven Teams collect data, analyze datasets, and suggest hypotheses and actions. It also involves answering questions from existing collected data and gathering insights to support operational and managerial decision making. Data Science has been around for a while, just as big data has been around for a while. Consider the Hubble, which has been sending us image data and scientists at CERN have been collecting Tera Bytes to uncover the secrets of inner workings of the universe.
Let's explore this following question in this blog posts: Is there are systematic approach to developing Data science capabilites that can assist an organization and its leaders in making data-driven decisions and run the business more effectively?
More formally, Data science is the process of formulating a quantitative question that can be answered with data, collecting and cleaning the data, analyzing the data, and communicating the answer to the question to a relevant audience. If we do want a concise definition, the following seems to be reasonable:
Data science is the application of computational and statistical techniques to address or gain insight into some problem in the real world.
The key phrases of importance here are “computational” (data science typically involves some sort of algorithmic methods written in code), “statistical” (statistical inference lets us build the predictions that we make), and “real world” (we are talking about deriving insight not into some artificial process, but into some “truth” in the real world).
Another way of looking at it, in some sense, is that data science is simply the union of the various techniques that are required to accomplish the above. That is, something like:
Data science = statistics + data collection + data preprocessing + machine learning + visualisation + business insights + scientific hypotheses + big data + (etc)
This definition is also useful, mainly because it emphasizes that all these areas are crucial to obtaining the goals of data science. In fact, in some sense data science is best defined in terms of what it is not, namely, that is it not (just) any one of these subjects above.
Data Science Experiment LifeCyle:
Every data science project starts with a question that is to be answered with data. That means forming the question is an important first step in the process. The second step is finding or generating the data you are going to use to answer that question. With that question solidified and data in hand, the data are then analysed, first by exploring the data and then often by modeling the data, which means using some statistical or machine learning techniques to analyse the data and answer your question. This is an iterative process, which means Data Science projects are a lot like broccoli. i.e fractal in nature in both time and construction. Early versions of the inquiry process, follow the same development process as later versions. At any given iteration, the process itself is a collection of smaller processes that often decompose into yet smaller analytics. After drawing conclusions from the overall analysis, the project has to be communicated to others. Decomposing the analytic problem at hand, into manageable pieces is the first step. Solving it would often times require combining multiple analytic techniques into a holistic, end-to-end solution. Engineering the complete solution requires that the problem be decomposed into progressively smaller sub-problems. Fractal Analytic Model embodies this approach. i.e At any given stage, the problem itself is a collection of smaller computations that decompose into yet smaller computations. When the problem is decomposed far enough, only a single analytic technique is needed to achieve the analytic goal.
The key takeaway is that Problem decomposition creates multiple sub-problems, each with their own goals, data, computations, and actions. Thus making, data science process an iterative one, where the different components blend together a little bit.
From a project management point of view, we can simplify the process into the following 7 steps and imagine jumping back and forth between these steps at execution time:
- Define the question of interest
- Get the data
- Clean the data
- Explore the data
- Fit statistical models
- Communicate the results
- Make your analysis reproducible
We use the Data Science Maturity Model as a common framework for describing the maturity progression and components that make up a Data Science capability. This framework can be applied to an organization’s Data Science capability or even to the maturity of a specific solution, namely a data product. At each stage of maturity, powerful insights can be gained and processes can improved or automated.
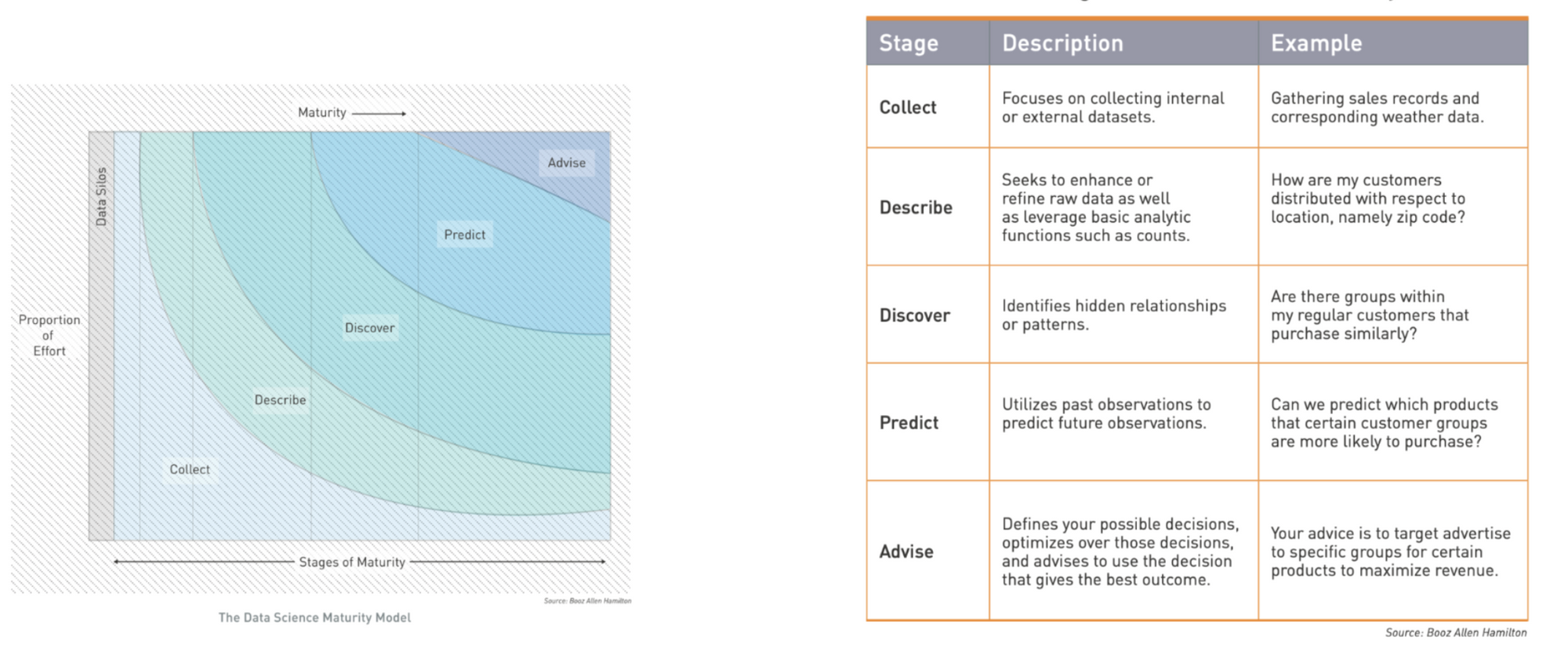
Descriptive and Diagnostic Analytics:
In descriptive analytics we simply describe what happened in the past using fundamental statistical techniques. This type of analytics is used in almost all types of industries and usually involves summarizing the data using statistical methods or looking for pre-existing patterns in the given data. i.e Usually, the datasets are unlabelled as we don't explicitly tell the correct output to the learning algorithm. Apart from basic statistical analysis, we can use various unsupervised learning algorithms to find patterns. e.g cluster analysis. The unsupervised algorithm can infer structure from data and can identify clusters in the data that exhibit similar data.
We can also data mining algorithms to perform basic diagnostics where we can for example try to understand the root cause of inefficiencies.
Example: Process Mining
An interesting example of monitoring and diagnostic data analysis is that of applying process mining techniques to process data (also known as event data). Doing so enables us to gain insight into the reality of our operational processes and helps identify process improvement opportunities. Here we take as input an event log and use it to discover business processes that are being executed on-ground. On a high-level this assists firms that are interested in continually re-evaluating their process behaviours so that, for instance, their business processes deliver better outcomes as anticipated by the process designs. One way to do this is to look at the past through a retrospective reasoning lens to understand what was common to process instances that delivered good outcomes. This approach involves discovering processes' existing behaviour and optimizing for positive future outcomes, thus lowering the risks and costs associated with negative outcomes. Process mining techniques can also allow organizations to check if the processes conform to rules and regulations and find bottlenecks for improving processes' efficiency across the organization.
Predictive Analytics
In Predictive analytics, we are interested in answering the fundamental question of 'Based on past experiences, can we predict what will most likely happen in the future?'. By prediction, we mean the general problem of leveraging the regularity of natural processes to guess the outcome of yet unseen events. It is worth noting that since we can't accurately predict the future, most of the predictions are probabilistic and depend on the quality of available data. Predictive Analytics is often enabled by supervised machine learning, where we use labelled data containing examples of the concepts we want to teach to the machine (i.e for predictive analytics we rely on machine learning, sometimes also known as `nonparametric statistics'). For example, we can predict housing sale prices in a given area by teaching the machine the relationship between different (input) features like size, interest rates, time of year and the sale price in the past.
According to Andrew Ng, almost all of AI’s recent progress is through one type of AI, in which some input data (A) is used to quickly generate some simple response (B). From a technical perspective machine learning is a great enabler for this kind of input-ouput mapping where a function of interest is learned using historical data.
Being able to input A and output B will transform many industries. The technical term for building this A→B software is supervised learning. These A→B systems have been improving rapidly, and the best ones today are built with a technology called deep learning or deep neural networks, which were loosely inspired by the brain.'' - Andrew NG
We can formalize the prediction problem by assuming a population of N individuals with a variety of attributes. Suppose each individual has an associated variable X and Y. The goal of prediction is to guess the value of Y from X that minimizes some error metric. We should note that having large amounts of labelled data is usually the bottleneck in applying machine learning to predict various types of behaviour.
Prescriptive Analytics:
Prescriptive analytics is the highest echelon in the data analytics continuum, as it is the one closest to making accurate and timely decisions. Prescriptive Analytics focuses on enabling the best decisions. Prescriptive analytics identifies, estimates, and compares all the possible outcomes/alternatives and chooses the best action toward achieving business objectives/goals. Thus, in prescriptive analytics the focus is on `actions' and decision support. i.e we take the given process goal into account and prescribe actions that optimize for a certain desirable outcome or it can enable decision support via for example appropriate use of recommendations.
Example: Decision Support via Intelligent Recommendations
Decision-making is the process of choosing among two or more alternative courses of action for the purpose of attaining one or more goals (For more details see Simon’s Theory of Decision-Making). Past execution data embodies rich experiences and lessons that we can use to develop models that can enable organisations to make better decisions in complex environments. For example, in business processes, we can make decisions about resource allocation based on the current context and ask what task to execute next in order to achieve optimal process performance. Several interesting enabling technologies exist for prescriptive analytics. We consider reinforcement learning where we try to maximise some sort of pre-defined utility or reward function that captures the goal(s) you care about in your application. e.g if we want to maximize returns of a certain investment portfolio then our reward function will be defined in a way that captures this objective and our algorithm will take actions that maximize the return.
Summary:
Data is key, as it fuels the all of the analytical process/options. its worth Investigating which datasets can be acquired or built internally. Once data is available, ideally, one should utilize all three approaches to establish a data driven firm. Firstly, build a dashboard in Power BI to empower every employee to visualize and query the company data (using co-pilot etc).
Secondly, do consider predictive analytics, as it is a mature technology. In predictive analytics, the goal is to model a function that is challenging to write down with explicit rules (e.g., determining whether an image contains a cat or a dog). Such predictive tasks can be framed as classification or regression problems.
Lastly, consider reinforcement learning to provide decision support. RL will learn a mapping policy that lets us perform actions in a given state. I would recommend read up on offline reinforcement learning, as it is more useful in real-world settings. Also remember, Automation is often resisted by old established industries, so you wanna test that hypothesis before throwing technology at the problem