
In a data-driven world, it’s tempting to think of AI as some kind of magic wand. But here’s the hard truth: most successful AI projects aren’t built on groundbreaking algorithms—they’re built on data as a foundation. And not just any data, but data that’s carefully collected, cleaned, and organized to work with the problem you’re solving.
The reality is, building data-centric AI solutions means making data strategy your top priority. For most organizations, the biggest challenge isn’t coming up with ideas for AI—it’s getting their data infrastructure and processes in shape to support those ideas. If you want to win with AI, you need to start with the boring stuff: pipelines, storage, and integration. Let’s talk about how to get that right.
The Myth of the Algorithm
One of the most common misconceptions about AI is that success is all about algorithms. Peter Norvig, a former director of Google Search, summed it up perfectly:
“Since ML algorithms and optimization are talked about more in literature and media, it is common for people to assume that they play larger roles than they do in the actual implementation process. … Optimizing an ML algorithm takes much less relative effort, but collecting data, building infrastructure, and integration each take much more work. The differences between expectations and reality are profound”.
This surprises a lot of people. They imagine AI breakthroughs coming from better math or clever tweaks to neural networks. In reality, most of the work happens before you ever train a model. Success in AI starts with a solid foundation: making sure your data is accurate, accessible, and connected to the problems you’re solving. Without that, even the smartest algorithms won’t get you very far.
This idea isn’t new. Think of it like Maslow’s hierarchy of needs but for data science: before you can focus on the flashy stuff at the top (like machine learning models), you need to nail the basics at the bottom—data collection, quality, and infrastructure.

The Data Challenge
Organizations face several challenges when it comes to working with data. The first is making sure the data you’re using is representative of the problem you’re solving. If your training data is biased or noisy, your model will be too. This sounds obvious, but it’s harder than it looks. Different types of AI projects need different kinds of data, and not every dataset is up to the job.
Before you dive into building models, ask yourself these three questions:
- Do we have the infrastructure to store and process the data we need?
- Are the datasets high quality and complete?
- Is there enough historical data to train a model that will generalize well?
If you can’t answer "yes" to all three, you’re not ready yet. AI thrives on good data. Without it, your models will struggle—or worse, fail entirely.
What to Do When Data Is Scarce
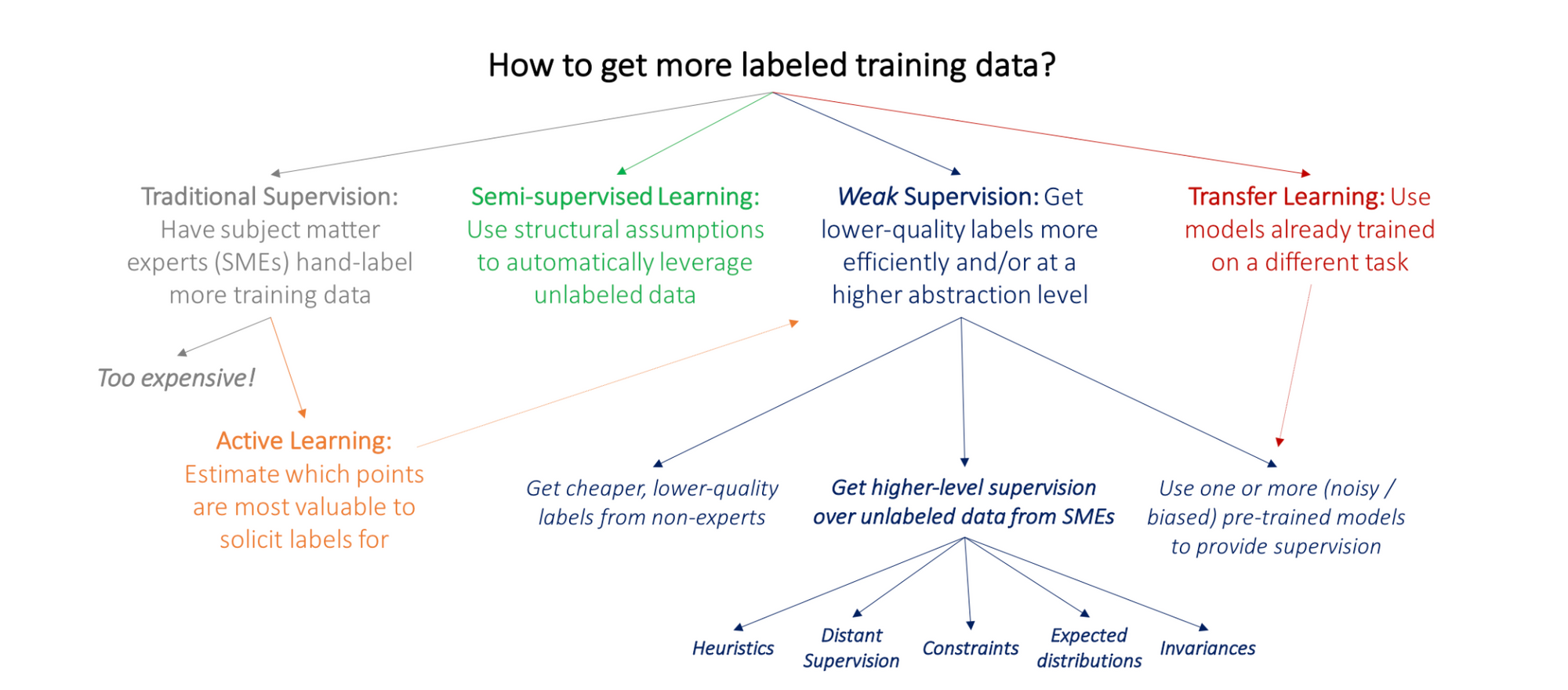
What if you don’t have enough data? That’s a common problem, especially for specialized tasks like medical imaging or niche domains. But it’s not a dealbreaker. There are strategies for making the most of limited data:
- Active Learning: Focus your labeling efforts on the most valuable data points, using subject matter experts efficiently.
- Semi-Supervised Learning: Combine a small labeled dataset with a larger pool of unlabeled data.
- Transfer Learning: Use pre-trained models as a starting point, adapting them to your specific problem.
- Generative Adversarial Networks (GANs): Create synthetic data to fill in gaps in your dataset.
- Weak Supervision: Use imperfect labels and clever algorithms to learn effectively despite noisy data.
These techniques can bridge the gap when data is scarce. But even with these tools, collecting more data is almost always worth the effort. Mature organizations know this, which is why they invest in long-term data acquisition strategies. Google and Baidu, for example, build free tools to gather valuable user data—a smart play that pays off in the long run.
Building a Data Flywheel
If you’ve read Jim Collins’ Good to Great, you’ve probably heard of the flywheel effect: a self-reinforcing loop that builds momentum over time. You can apply the same idea to data. A Data Flywheel works like this:
- Collect data from apps, tools, and processes.
- Store it securely in a centralized data lake.
- Use it to build data-driven products and features.
- Deploy those products to generate even more data.
With each turn of the flywheel, your data gets better, your models get smarter, and your competitive edge grows stronger. Companies like Amazon and Google have mastered this, creating feedback loops that continuously improve their products while widening their moats.
The Foundations of Success
Here’s the bottom line: most AI projects don’t fail because of bad algorithms—they fail because of bad foundations. If you want your AI projects to succeed, you need to:
- Ensure data availability: Start with the right quality and quantity of data.
- Build infrastructure: Create the pipelines and storage systems to manage it effectively.
- Maintain data quality: Regularly monitor and clean your data to keep it usable.
These steps sound simple, but they’re where most of the work happens. Get them right, and you’ll set yourself up for success.
The Boring Stuff Matters ! It’s easy to get excited about AI’s potential to transform industries, but the truth is, most of the magic happens behind the scenes. It’s the boring stuff—data infrastructure, cleaning, and pipelines—that lays the groundwork for everything else. And while it might not be glamorous, it’s what separates the AI winners from the also-rans.
If you want to build AI that works, start with the data. Do the hard, unglamorous work of making sure your foundation is solid. Because in the end, the best AI solutions aren’t the ones with the fanciest algorithms—they’re the ones built on the strongest data.