"The purpose of (scientific) computing is insight, not numbers". - Richard Hamming
What is a data product? At its core, it’s something that turns raw data into actionable insights, predictions, or automation. Think of dashboards, recommendation systems, fraud detection tools, or personalized learning platforms. They all have one thing in common: they take data, process it, and turn it into something useful. And yet, as simple as that sounds, building a great data product is anything but simple.
The key components of a data product—data ingestion, processing, analytics, and a user interface—might look straightforward on paper. But getting all those pieces to work together in a way that actually provides value? That’s the hard part. And it’s also why data products represent a fundamental shift in how we think about software.
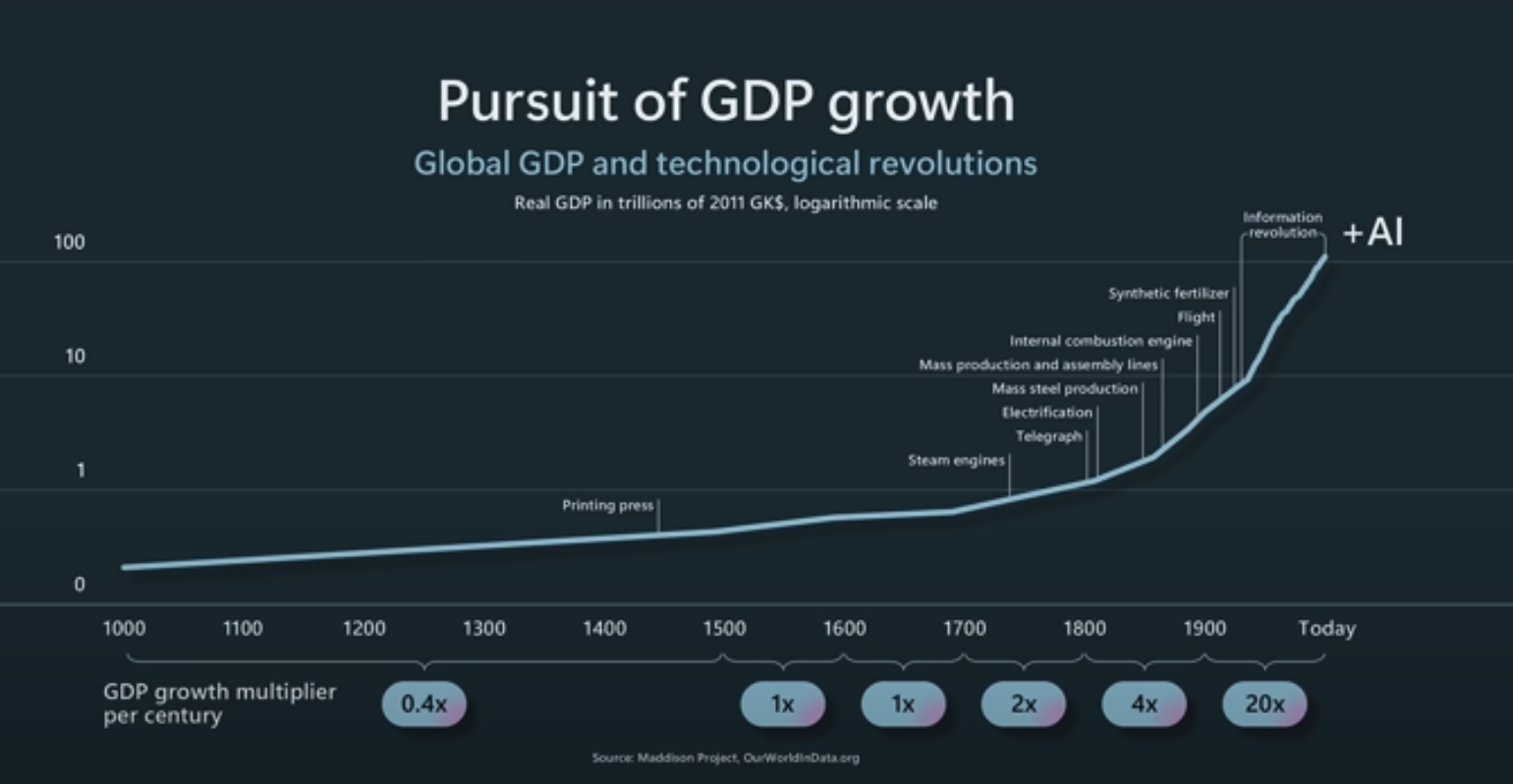
To understand why data products matter so much, you have to zoom out a bit. Computers weren’t always the powerful tools we know today. In fact, one of the reasons they exist is because of a tedious, manual problem: the U.S. census. Back in 1880, it took eight years to process the data, and that delay was a serious bottleneck. Enter Herman Hollerith, who invented a system to punch census data onto cards, making it possible to process vast amounts of information much faster. That invention didn’t just solve a specific problem—it laid the foundation for modern computing. It’s a story that repeats itself: many major leaps in computing have been driven by the need of business and firms to make sense of more data, faster.
"John Shaw Billings, a physician assigned to assist the Census Office with compiling health statistics, had closely observed the immense tabulation efforts required to deal with the raw data of 1880. He expressed his concerns to a young mechanical engineer assisting with the census, Herman Hollerith, a recent graduate of the Columbia School of Mines. On September 23, 1884, the U.S. Patent Office recorded a submission from the 24-year-old Hollerith, titled “Art of Compiling Statistics.” By progressively improving the ideas of this initial submission, Hollerith would decisively win an 1889 competition to improve the processing of the 1890 census. The technological solutions devised by Hollerith involved a suite of mechanical and electrical devices. The first crucial innovation was to translate data on handwritten census tally sheets to patterns of holes punched in cards. As Hollerith phrased it, in the 1889 revision of his patent application. This process required developing special machinery to ensure that holes could be punched with accuracy and efficiency. - Computers have an unlikely origin story: the 1890 census"
Here’s what makes data products so powerful: they’re often part of a feedback loop. Take Toutiao, a Chinese content curation app. The more people use it, the more data it collects about their preferences. The more data it collects, the better its recommendations become. And the better its recommendations, the more people use it. This virtuous cycle isn’t just a side effect of data products—it’s their defining feature.
"Simply put, the more users use your product, the more data they contribute. The more data they contribute, the smarter your product becomes. The smarter your product is (e.g., better personalization, recommendations), the better it serves your users and they are more likely to come back often and contribute more data — thus creating a virtuous cycle. By building an addictive product, Toutiao generates engagement data from their users. That data is fed into Toutiao’s algorithms, which in turn further refines the products’ quality. Ultimately, the company plans to use this virtuous cycle to optimize every stage of what they call the “content lifecycle”:" Creation, Curation, Recommendation and Interaction. — The Hidden Forces Behind Toutiao: China’s Content King
This feedback loop isn’t limited to consumer apps. Think about a weather app. It doesn’t just tell you the forecast; it might suggest what to wear, remind you to pack an umbrella, or even offer personalized vacation advice. Every interaction generates user data in the form of interactions and feedback, and every bit of data that data can be levearged to make the product smarter.
But here’s the thing: building a data product that can harness this feedback loop requires more than just good algorithms. You need great data, thoughtful design, and a team that understands how to bring it all together.
Today, we’re at a similar inflection point. The rise of the internet, social networks, and cheap storage means we’re drowning in data. And while that data has the potential to unlock incredible value, it’s useless without the right tools to extract it. A decade ago, the buzz was all about big data. Companies rushed to build data warehouses and business intelligence tools, hoping to extract insights that would drive better decisions. For many, it worked. Instead of relying on gut feelings, businesses started using dashboards and metrics to optimize their operations and business processes.
But dashboards were just the beginning. As data science matured, companies began to see the potential for more advanced tools—tools that didn’t just report the past but predicted the future. This shift gave rise to a new generation of applications powered by machine learning and AI. The focus isn’t just on analyzing data; it’s on building systems that can learn and adapt. These systems don’t just solve well-defined problems—they help businesses discover new opportunities, optimize processes, and even automate entire workflows.
A data product is something that can only exist because of the analysis of some underlying data set. Maybe you can argue with that, or maybe you want to, but I think the point I’m trying to make here is that we’re able now in 2019 to build an entirely new class of application. And we’ve been able to do this for a while. It was just much more expensive. It was out of reach. - Hilary Mason
For all their potential, data products aren’t easy to build. One challenge is that the tools and technologies are still evolving. Titles like “data engineer” or “MLOps specialist” might sound fancy, but they reflect the messy reality of a field that’s still figuring itself out. What does it even mean to be a data scientist? The answer depends on who you ask—and what tools they’re using.
Another challenge is that many companies try to outsource their data problems. They buy off-the-shelf solutions instead of investing in in-house expertise. That might work in the short term, but in the long run, it’s a losing strategy. Companies that treat data as a core capability—like Toutiao—gain a competitive edge that’s hard to replicate.
And then there’s the biggest challenge of all: making sure the data product actually provides value. A data product isn’t just a collection of features. It’s a system that combines data, context, and insight to solve a specific problem. Getting that right requires more than technical skill. It requires a certain wisdom of sort from leadership. Successful data products require data science's secret sauce, which includes data, context, domain expertise and a great team for executing the ideas.
In practice, data products can range from dashboards and recommendation systems to AI-powered applications like fraud detection systems, personalized learning platforms, or even predictive maintenance tools. They are often characterized by the following key components:
1. Data Ingestion: Collecting data from various sources (e.g., databases, APIs, sensors).
2. Data Processing: Cleaning, transforming, and organizing data into a usable format.
3. Analytics or Models: Applying algorithms, statistical methods, or machine learning models to extract insights or make predictions.
4. User Interface: Presenting the insights or results in a user-friendly format, often via dashboards, APIs, or applications.
As we look ahead, the future of data products is bright but complex. The next wave of innovation will likely focus on building tools that are not only smarter but also more aligned with human values. That means thinking deeply about concepts like explainability, fairness, and trust.
One of the most exciting areas of exploration is the idea of using algorithms not just to analyze data but to create new knowledge. Imagine a system that doesn’t just predict the weather but helps us understand the underlying patterns driving climate change. Or a healthcare app that doesn’t just diagnose diseases but suggests entirely new treatments. These aren’t just hypothetical scenarios—they’re the natural evolution of data products.
Stealing Steve Job's Analogy. At their best, data products are like bicycles for the mind. They amplify our ability to think, make decisions, and create. And just like bicycles, they have the potential to transform how we live and work. The challenge isn’t just building these tools—it’s using them responsibly. As we continue to innovate, we need to keep asking ourselves: are these tools helping us move toward abundance and a better future? If we can answer yes, then we’re on the right track.
Where does ML/AI buzz come into all of this? Well that's a long topic of discussion. But let me close on a remark that computers have always been bicycles for mind and that Net positive impact that technology can have on society as well as create abundance.