

Business processes assist organizations in organizing activities that deliver business value, usually in the form of a product or a service. Over the last few years, some of the focus of BPM research has shifted to supporting knowledge-intensive processes. Such processes are typically complex, unpredictable, unstructured (with predefined fragments, where activities cannot be anticipated or modeled in advance), and are dependent on knowledge workers as process participants. Instead of assuming rigid structures of processes, knowledge-intensive processes (KIPs) are characterized by activities that cannot be planned a priori. KIPs involve knowledge workers who deal with the acquisition, analysis, and manipulation of information and are considered the most valuable assets of today's organizations.
Knowledge workers are highly trained and have specialized expertise in performing complex tasks autonomously, making them a key asset for modern businesses. They typically rely on their experience and domain expertise to accomplish business goals. Their work is less characterized by explicit procedures and more by creative thinking, which usually cannot be planned a priori.
Clinical Decision Support
A good example of knowledge work is clinical decision-making, which is highly case-specific and requires a knowledge-driven approach. It depends on highly specific medical domain knowledge and evidence that emerges from patient test results and sensors. Knowledge-intensive processes aim to provide support to knowledge workers in the form of recommendations that facilitate decision-making.
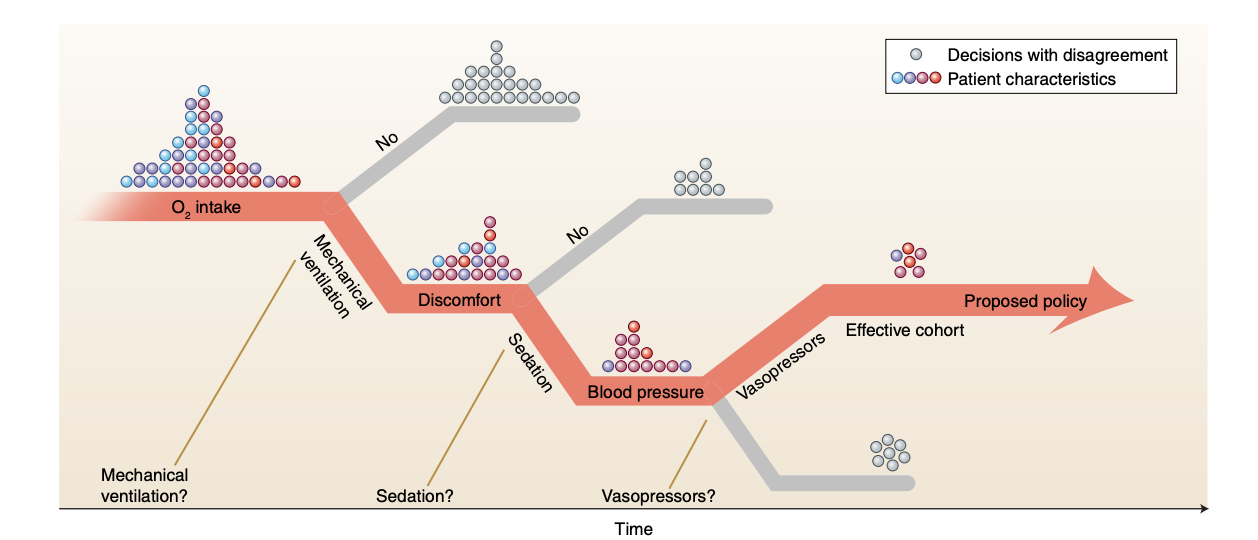
We choose the example of sepsis treatment to showcase the entire spectrum of process management, which ranges from fully structured to fully unstructured activities. Sepsis is a dangerous condition that costs billions of dollars each year to treat. Managing this disease is quite challenging for clinicians and consists of administering intravenous fluids and vasopressors, which can greatly influence the outcome. We argue that a data-driven approach to discovering sepsis treatment strategies is a good representative for evaluating the recommendation theory for knowledge-intensive processes proposed in the previous section. We show that by using reinforcement learning (RL), our proposed framework is useful for solving the "knowledge worker decision support" problem in the most complicated healthcare setting. Specifically, we demonstrate how we can leverage event and effect logs to discover effective medical treatment strategies.
Decision Modelling with Offline Reinforcement Learning
Traditional reinforcement learning (RL) has shown significant promise in solving complex tasks involving high-dimensional state spaces, actions, and long-term rewards (such as Dota 2 and robotics). However, much of RL's success so far has been in academic environments where access to simulators is assumed, and experiments are performed on simulated benchmark environments. Real-world datasets can be massive, with thousands of varying feature types, high-dimensional action spaces, and the additional challenge of evaluating the performance of models before deployment.
However, the fact that reinforcement learning algorithms provide a fundamentally online learning paradigm is also one of the biggest obstacles to their widespread adoption.
Offline Reinforcement learning (also referred to as safe or batch reinforcement learning) is a promising sub-field of RL which provides us with a mechanism for solving real world sequential decision making problems where access to simulator is not available [1]. Here we assume that learn a policy from fixed dataset of trajectories with further interaction with the environment (agent doesn't receive reward or punishment signal from the environment). It has shown that such an approach can leverage vast amount of existing logged data (in the form of previous interactions with the environment) and can outperform supervised learning approaches or heuristic based policies for solving real world - decision making problems. Furthermore, offline RL algorithms when trained on sufficiently large and diverse offline datasets can produce close to optimal policies(ability to generalize beyond training data).
Markov Decision Process (MDP) formulation
To apply reinforcement learning techniques to the sepis management problem, we need to pre-process the data and define three things: a state space, an action space, and a reward function.
Patient cohort:
MIMIC-III ('Medical Information Mart for Intensive Care') is a large open-access anonymized single-center database which consists of comprehensive clinical data of 61,532 critical care admissions from 2001–2012 collected at a Boston teaching hospital. Dataset consists of 47 features (including demographics, vitals,
and lab test results) on a cohort of sepsis patients who meet the sepsis-3 definition criteria.
PreProcessing:
In our implementation, we rely on MIMIC-Extract [3] which Offers guidelines and establishes a community standard for pre-preprocessing the MIMIC dataset for various machine learning tasks. We have included patients with age > 15, whose ICU stay is between 12 hours and 10 days resulting in 34,472 patients representing a diverse cohort. Further we excluded entries containing outliers and missing values. Lastly for every patient time-stamped physiological measurements are aggregated (e.g hourly heart rate, arterial blood pressure, or respiratory rate) into one hour windows, with the mean or sum being recorded when several data points were present in one window.
State representation:
Our feature set(representing the physiological state of the patient patient) is the input to our RL based decision making system. It consists of four static features (like gender, ethnicity, age etc) concatenated with six time varying patient vitals (e.g., heart rate, blood pressure, respiratory rate, oxygen saturation level). After feature encoding, Our MDP state is thus all the relevant patient covariates represented by a feature vector of size 21 x 1 updated at each time step.
Actions space:
The pre-processed dataset includes hourly indicators of various device and drug treatments provided to the patient overtime. These interventions are commonly used in ICU and can have significant impact on patient mortality. Our action (or treatment) space consists of five discrete actions, combination of them represents various interventions when patient has been admitted in ICU. To simply things we don't consider the exact dosage of each intervention. Our selected interventions include: mechanical ventilation administration, vasopressor administration, adenosine administration, dobutamine administration and dopamine administration.
Reward function
RL agent's goal is to learn a policy which maximizes the total reward collected over time. We define our reward function by ‘in-hospital mortality’ indicator as our reward function. Our agent receives no intermediate reward while training and a positive reward is given at the end only if the patient survives and a negative reward if the patient dies.
Model Implementation
We define an optimal policy as a mapping from the patient's history H (history of their measurements and treatments to date) to the next treatment decision in a way that leads to optimal outcomes in the long run. In this step, using off-policy RL algorithms, we find an optimal policy that recommends the optimal treatment path.
Several offline or batch RL algorithms have been proposed in the literature. In our experiment, we focus on popular state-of-the-art algorithms such as Deep Q Learning (DQN), Double Deep Q Learning (DDQN), DDQN combined with BNC, Mixed Monte Carlo (MMC), and Persistent Advantage Learning (PAL). Using these methods, we train an RL policy to recommend the optimal treatment path for a given patient.
Evaluating the performance of the newly trained model is important. However, since our goal in RL is policy optimization, we evaluate and report the performance of several policies (where a policy represents the actions that the model will pick). In our implementation, we rely on various well-known off-policy and counterfactual policy evaluation (CPE/OPE) metrics to provide the expected performance of the newly trained RL model without having to deploy it. Evaluating it otherwise typically requires launching numerous A/B tests, which can take several weeks to collect new observational data and is infeasible in domains like healthcare due to safety concerns.
Results
In our experiments, we divide the data with 0.6-0.4 for train and evaluate set respectively. We profile various deep RL methods (such as DQN, DDQN, MonteCarlo etc.) and compare the estimates for the values of three different policies: RL policy, clinician policy and random intervention policy (which takes actions uniformly at random). We then trained 100 RL agents and picked the best one based on a CPE metric such as Weighted importance sampling (WIS). We are interested in evaluating the potential improvement a new policy can bring in terms of reduction in patient mortality. Our results show that our proposed framework is useful in coming up with policies that can offer treatment recommendations and suggest small improvements over existing expert policies, leading to good outcomes(as measured by patient mortality). We further show that our proposed framework is adaptable enough to balance between the structured and unstructured aspects of the knowledge Intensive Processes by providing support for repetitive tasks yet be flexible enough to facilitate creative aspects of problem solving during execution at run-time.
Discussion:
In real world settings accurate OPE estimation is challenging due to several reasons. Firstly, in healthcare settings we have problem of observing sparse rewards. i.e decisions made now have an impact several time steps later measured by the impact on outcome. Having sparse outcomes makes it challenging to asses newly learned policies and the effect an individual decision by a physician can have on the patient. Secondly, the statistical tools for evaluation like Importance Sampling estimators have limitations and can be unreliable in scenarios where data is limited. We should note that to learn an optimal policy, even if we have large amounts of data available, we require it to be sufficiently diverse as the number of sequences that match the evaluation policy decays exponentially leaving only a tiny fraction of trajectories (after being assigned non-zero weight) that match the treatments that our policy recommends. This results in high-variance estimates of evaluation policy. Lastly, behaviour policies are not known and model terms are hard to estimate. We should also note that each of the estimator comes with a tradeoffs between bias and variance in off-policy evaluation, so we can't rely on a single estimator for evaluation in the sepsis management problem. Due to all these challenging aspects, we have to take special care in evaluating the newly proposed policies.
Even though here has been a lot of excitement around using RL for adaptive decision making, we remain cautious in being overly optimistic and making the claim that our proposed RL system can fundamentally discover new treatments. We should rather stick to picking policies that don't significantly differ from those present in the given historical dataset. Our treatment recommender system can suggest small changes to refine existing clinician policies. Fundamentally, we see our framework playing the role of providing decision support and recommending actions leading to good outcomes (as measured by patient mortality). We recommend consulting the domain expert at each stage, for setting up the RL problem in the right way, picking the right the reward scheme and expert evaluation of the final learned policy.
Having said all of that, RL still remains a powerful tool for optimizing sequential decisions which can provide us with mechanism to improve upon and refine existing expert policies. Overall, in our experiment we show that given a sufficiently rich dataset generated by a behaviour policy, Offline Reinforcement learning can learn optimal policies that can recommend sensible actions to the knowledge worker involved in the clinical car process.
Conclusion:
Supporting knowledge work when rigid definitions of process models are not available or cannot be designed apriori (with structured or unstructured data) remains an interesting challenge for the BPM community to tackle. Retrospective data that represents expert decisions in the past offers an opportunity that can be exploited for building a decision support solution for knowledge workers. In this work, based on recent advances in deep reinforcement learning we proposed an RL based decision framework, that can provide recommendations to knowledge workers given a case state. We demonstrated the efficacy of our approach by conducting an experiment on a real world sepsis treatment ICU dataset.
See paper and code for more detailed description of results :
References:
[1] Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems