
Before data modelling or any sort of data analysis its important to manually explore what data you have at hand. EDA always precedes formal (confirmatory) data analysis. EDA is useful for:
- Detection of mistakes
- Checking of assumptions
- Determining relationships among the explanatory variables
- Assessing the direction and rough size of relationships between explanatory and outcome variables
- Preliminary selection of appropriate models of the relationship between an outcome variable and one or more explanatory variables.
Most of the time these datasets are huge and available remotely at a server. Command line as the advantage of providing a so-called read-eval-print-loop (REPL) and can play a complimentary role in your existing toolset of data analysis.
Most folks are already familiar with commands like pwd, echo, cd and head. In this post we will look at some of new command line utilities that can be used to:
- Look at your data - its properties and total entries etc.
- compute descriptive statistics from your data
Warm-Up:
There are various way of getting the data APIs, web-scrapping and using direct downloads are the common ways. e.g curl allows us to download a file located on some server.
curl -s http://www.gutenberg.org/files/64207/64207-0.txt -o med8.txtthis downloads a random textbook from gutenberg website. we can check the author and title as follows:
grep -i Title med8.txt | head -n 1
which will output: Title: Of Medicine in Eight Books
grep -i Author med8.txt | head -n 1
output: Author: Aulus Cornelius Celsus
tr ' ' '\n' < med8.txt | grep Medicine | wc -loutput: 10 #the no. of time Medicine appears in the book
Can we count what the most common words appearing in the book? Yes, Try the following:
< med8.txt tr '[:upper:]' '[:lower:]' | grep -oE '\w{2,}' | grep -E '^.*$' | sort | uniq -c | sort -nr | head -n 10Data Formats:
Data comes and it comes in various formats like JSON, XML and CSV. In this post we stick with CSV which is a a delimited text file that uses a comma to separate values.
Kaggle is another interesting website for downloading datasets and there are various useful datasets available in nice formats. Lets go ahead and download a weblog dataset [1] which represents a log of server requests and is available in csv format.
Initial Exploration:
A useful utility to explore datasets in csv format is 'csvkit'. Lets go ahead and install it by running:
pip install csvkitonce installed we can go ahead and check if the file has a header:
head weblog.csv | csvlook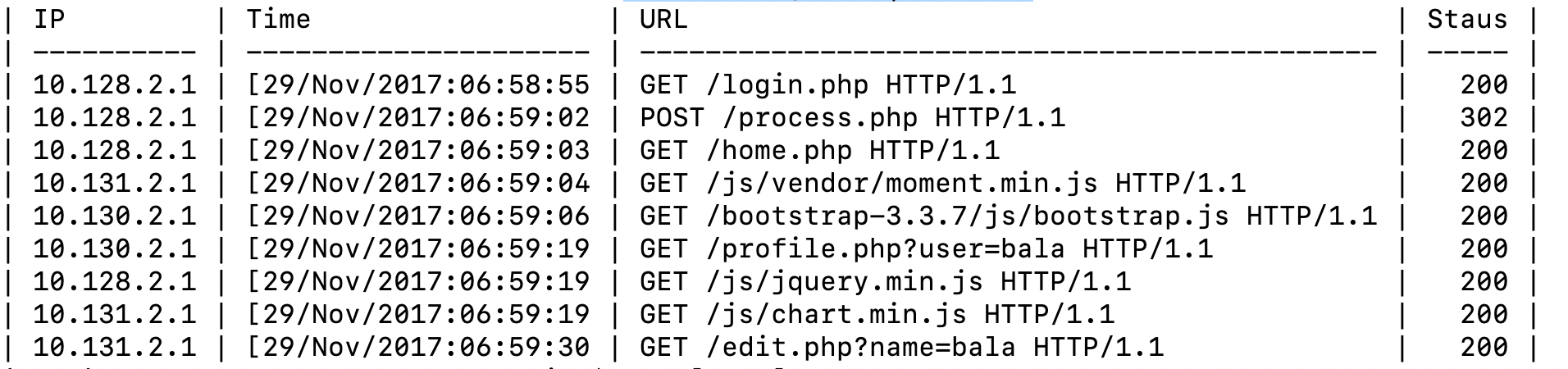
alternatively we can also make use of sed:
< weblog.csv sed -e 's/,/\n/g;q'
we can see the main columns are IP, Time, URL, Response Status.
To check number of rows:
wc -l weblog.csv
output: 16008 weblog.csv
Let's say we want to filter and have a look at login requests. we can make use a of common utility known as grep.
grep /login.php weblog.csv
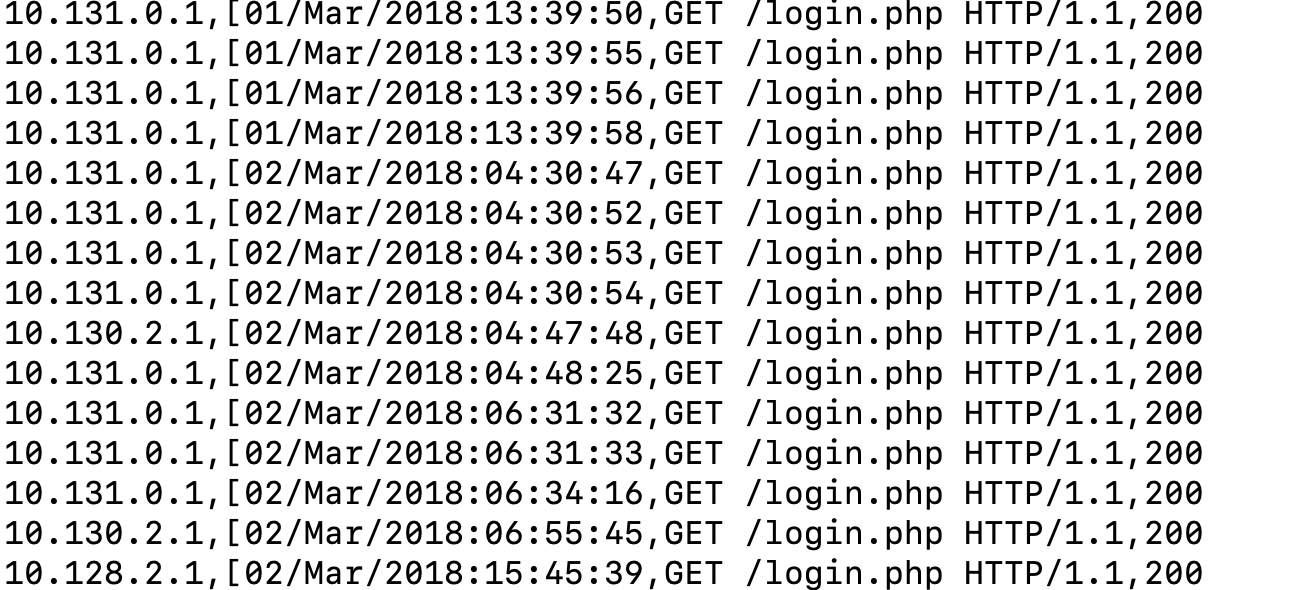
Turns out there are too many such lines. Here we can make use of 'less' which allows us to scroll horizontally without loading the whole thing in memory.
less -S weblog.csvPress G to reach the end of file. and For a nicer neat print you can try
< file.csv csvlook | less -S
what if the file is present on a remote server? simple append
ssh myserver weblog.csv | grep /login.php and again use 'less' to avoid streaming the whole (potentially BIG !) file on your machine.
How about if we want to extract second and third column?
cut -d , -f 2,3 weblog.csvDescriptive Statistics:
How about some basic stats? csvstat provides an awesome summary:
csvstat weblog.csv
1. "IP"
Type of data: Text
Contains null values: False
Unique values: 16
Longest value: 10 characters
Most common values: 10.128.2.1 (4257x)
10.131.0.1 (4198x)
10.130.2.1 (4056x)
10.129.2.1 (1652x)
10.131.2.1 (1626x)
2. "Time"
Type of data: Text
Contains null values: False
Unique values: 7307
Longest value: 26 characters
Most common values: cannot (167x)
[16/Nov/2017:15:51:03 (44x)
[16/Nov/2017:16:12:16 (28x)
[16/Nov/2017:16:17:31 (28x)
[17/Nov/2017:05:53:36 (26x)
3. "URL"
Type of data: Text
Contains null values: False
Unique values: 314
Longest value: 76 characters
Most common values: GET /login.php HTTP/1.1 (3284x)
GET /home.php HTTP/1.1 (2640x)
GET /js/vendor/modernizr-2.8.3.min.js HTTP/1.1 (1415x)
GET / HTTP/1.1 (861x)
GET /contestproblem.php?name=RUET%20OJ%20Server%20Testing%20Contest HTTP/1.1 (467x)
4. "Staus"
Type of data: Text
Contains null values: False
Unique values: 13
Longest value: 12 characters
Most common values: 200 (11330x)
302 (3498x)
304 (658x)
404 (251x)
No (167x)
Row count: 16007
we can further check for stats like min, mean, max etc. e.g to find out the unique value in each column we can start with 'csvstat' which gives unique values for each column:
csvstat weblog.csv --unique
this will output:
- IP: 16 2. Time: 7307 3. URL: 314 4. Staus: 13
Data Wrangling and Cleaning:
The data we acquire is often noisy and messy. It comes with missing values, inconsistencies, errors. We need tools that can help clean that data. One way is to use sed, which can do all sorts of interesting things using the power of regular expression.
To get started, let's say we want to remove first few lines with sed:
< weblog.csv sed tail -n +4lets say we want to search and replace a certain piece of text.
sed s/REGEX/SUBSTITUTION/'where REGEX is the regular expression we want to apply for search, and SUBSTITUTION is the text we want to substitute the matching text(if found).
sed 's/.*HTTP/HTTPS/' weblog.csv Reordering of Columns is a common operation:
< weblog.csv csvcut -c Time,URL,Staus,IP | head -n 5 | csvlook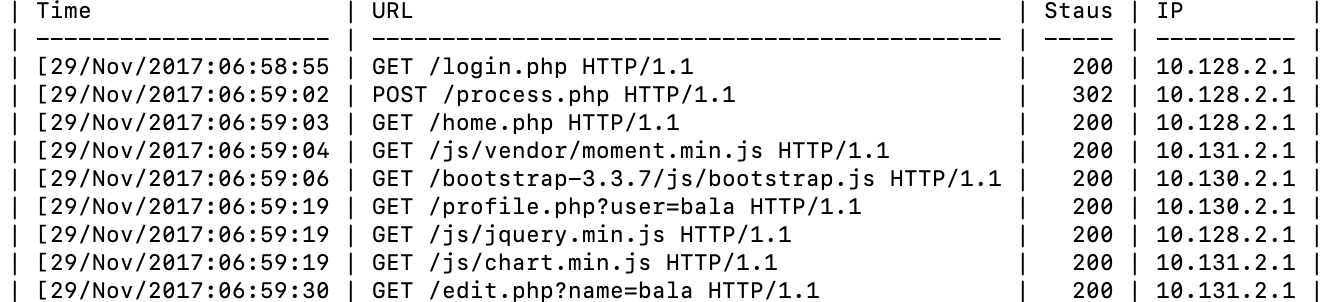
How about filtering(removing) the 200 status row (likely not useful for degbugging when looking at logs:
csvgrep -c staus -i -r "200" weblog.csv | csvlook
< weblog.csv awk -F, '($4 == 404)' | csvlook -IThis filters the rows and finds the ones with 404 status code:
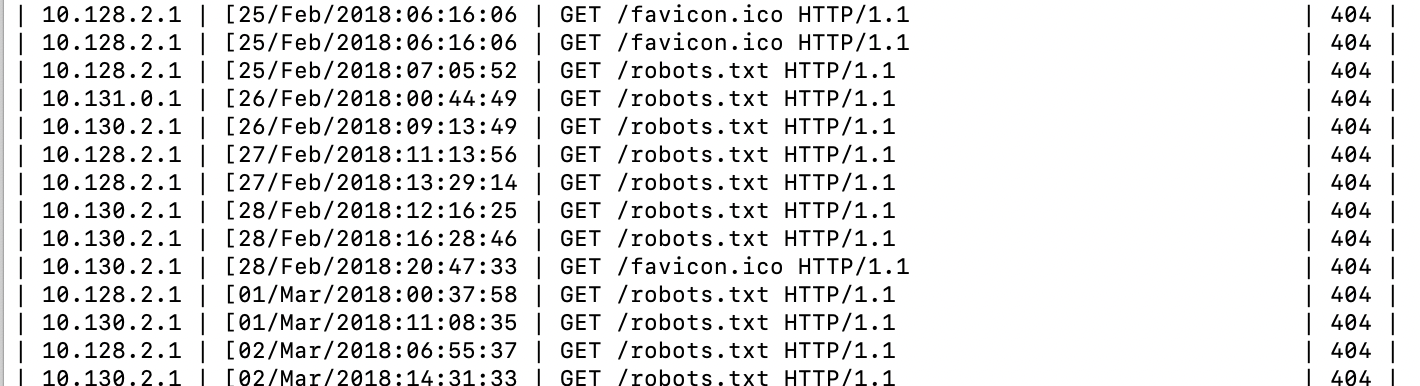
Conclusion:
Linux is fun and provides some really nice tools for familiarize yourself with the data. Thats the first step for extracting any value out of that dataset. We started with some tools that can be used for inspecting the data and its properties. We then learned how to compute basic descriptive statistics. In the next post we will look at exploring data via visualisations.
[1] https://www.kaggle.com/shawon10/web-log-dataset?select=weblog.csv
[2] https://www.datascienceatthecommandline.com/1e/
[3] https://missing.csail.mit.edu/2020/data-wrangling/
[4] https://drive.google.com/file/d/1DEJDUeDM5XXM_N-4QCNxuRwtgws0nzzk/view