
Most of the articles on data analytics would have convinced you by now that companies are capturing only a fraction of the potential value from the available data and that many organizations face challenges in incorporating data-driven insights into day-to-day business processes. It is also common to hear that Data analytics are changing the basis of competition and that data is now a critical corporate asset.
Beyond the hype, whats actually happening? well, its true that being Data-driven enables new capabilities for organizations e.g it allows them to[1]:
- Predict market trends as well as trends in the operating context
- Identify likely customers from publicly available datasets
- Generate new service offerings based on current customer behaviour
- Personalize the client experience (touchpoint adaptation)
- Adapt service delivery modalities, teams and organizational structures to the context
- Generate data-driven process/service variants
- Leverage provisioning histories to achieve optimal service provisioning
- Use data streams to assess service impact, and thus support real-time
- Monitoring and compliance management for various processes
But why then do companies struggle to transform themselves and take advantage of all these new technologies? Well developing a robust Data Science capability requires a shift in culture where you have to make sure that the correct processes are in place, people are on-board, and an operating model that is constantly being updated to achieve the desired maturity level. We will leave these aspects for discussion in another post. Instead we focus on understanding some fundamental capabilities that data science has to offer.
What is data science anyway?
"Data Science supports and encourages shifting between deductive (hypothesis-based) and inductive (pattern-based) reasoning. This is a fundamental change from traditional analytic approaches. Inductive reasoning and exploratory data analysis provide a means to form or refine hypotheses and discover new analytic paths. In fact, to do the discovery of signifcant insights that are the hallmark of Data Science, you must have the tradecraft and the interplay between inductive and deductive reasoning. By actively combining the ability to reason deductively and inductively, Data Science creates an environment where models of reality no longer need to be static and empirically based. Instead, they are constantly tested, updated and improved until better models are found. These concepts are summarized in the figure, The Types of Reason and Their Role in Data Science Tradecraft." - Field Guide to data Science
For practical purposes we can even run with a similar definition (by J. Kolter at CMU):
> Data science = statistics + data collection + data preprocessing + machine learning + visualization + business insights + scientific hypotheses + big data + (etc)
Without complicating things, the three major types of Analytics are Descriptive, Predictive and Prescriptive. We try to understand these in the following sections:
Data Mining and Descriptive Analytics:
Here we describe what happened in the past. This type of analytics is used in almost all types of industries and usually involves looking for patterns in pre-existing datasets. Usually the datasets are unlabelled as we don't explicitly tell the correct output to the learning algorithm. Apart from basic statistical analysis, we can use various unsupervised learning algorithms to find patterns. e.g cluster analysis. The unsupervised algorithm can infer structure from data and can identify clusters in the data that exhibit similar data.
Case Study: Process Mining: An interesting case study is process mining where we take as input event logs and use them to discover business processes that are being executed on-ground. I have discussed process analytics and process mining in some of my previous posts. Essentially it tries to solve the problem of firms needing to continually re-evaluate their behaviours so that, for instance, their business processes deliver better outcomes. One way to do this is to look at the past, through a retrospective reasoning lens to understand what was common to process instances that delivered good outcomes. This allows us to discover the existing behaviour of processes and optimize for positive future outcomes, thus lowering the risks and costs associated with negative outcomes.
Predictive Analytics
Here we ask the fundamental question 'What will happen in the future?'. Its worth noting that since we can't accurately predict the future, most of the predictions are probabilistic and depend on the quality of available data. Predictive Analytics is also known as supervised machine learning where we used labelled data containing examples of the concepts we want to teach the machine. For example we can predict housing sale prices in a given area by teaching the machine the relationship between different (input) features like size, interest rates, time of year and the sale price in the past. Having large amounts of labeled data is usually the bottle-neck in applying machine to predict various types of behaviour.
According to andrew Ng, almost all of AI’s recent progress is through one type of AI, in which some input data (A) is used to quickly generate some simple response (B). What he is describing is what mostly goes on in machine learning, which is why its true that the impactful AI technology today is machine learning.
Being able to input A and output B will transform many industries. The technical term for building this A→B software is supervised learning. These A→B systems have been improving rapidly, and the best ones today are built with a technology called deep learning or deep neural networks, which were loosely inspired by the brain. — Andrew NG

So we see just by using a few recent advances in machine learning can be used to solve a tremendous variety of problems and deep learning(active area of research) holds potential in pushing the boundaries even further[1].
Prescriptive Analytics for Effective Decision Making
Past execution data embodies rich experiences and lessons that we can use to develop models that can enable organisations to make better decisions in complex environments. e.g In business processes we can make decisions about resource allocation based on the current context and ask what task to execute next, in order to achieve optimal process performance. One of the major Enabling technologies here is reinforcement learning where we try to maximise some sort of pre-defined utility or reward function that captures the goal(s) you care about in your application. e.g If we want to maximize returns of a certain investment portfolio then our reward function will be defined in a way that captures this objective and our algorithm will take actions that maximize the return.
Case Study: Data Science at NyTimes:
The Process:
Every data Science Project starts with a question that is to be answered with data. The second step is gather the data you are going to use to answer that question. With the question and data sorted, we can move on to data analysis, where we start first by exploring the data and then often by modeling the data, which means using one of the above described techniques to analyse the data and answer the desired question question. After drawing conclusions from this analysis, the project has to be communicated to others. Note that this is not always a forward going process. Rather, all of this is like broccoli (meaning fractal in nature) making it an iterative Process.
We use the Data Science Maturity Model as a common framework for describing the maturity progression and components that make up a Data Science capability. This framework can be applied to an organization’s Data Science capability or even to the maturity of a specifc solution, namely a data product. At each stage of maturity, powerful insight can be gained. - Data Science field guide
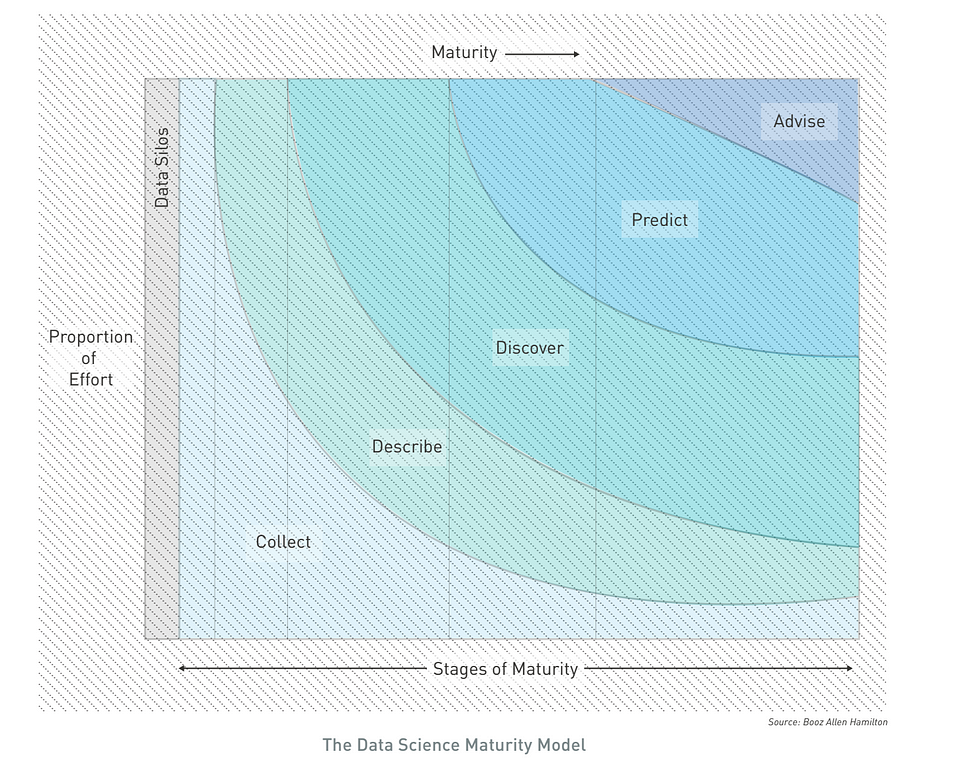
Future Trends:
I think we'll see a number of things happen: Data generation will only increase and Data-driven organisations will become the norm. However, Tackling data challenges and getting value out of it will still remain tricky. Organizations will have to know, what data to collect from day 1 and how to create a culture of Experiment driven optimisation of operations and process designs.
Further, I suspect the excitement around Machine learning will decrease as supervised ML will likely become a commodity technology like databases where its easy for average joe programmer to integrate it into the existing products. Alsom some of the basic data analysis tasks would be automated by startups that are domain specific. i.e domain specific startups will solve some of the data challenges Data will analysed in the context it was generated. Its interesting that even with a lot of decision off-loading creative business strategy will still be still be left to humans.
Organisations need to make effective decisions about various execution strategies to pursue, especially in adversarial settings. This is a problem that cannot be solved using traditional machine learning techniques, because the right datasets are usually missing. New sets of technologies are needed for such scenarios we need to assist business leaders for effective reasoning on a strategic level. e.g we need to build simulated systems that leverage AI techniques such as the classic Knowledge representation combined with Game Tree Search(used in AlphaGo) and Goal Modelling to
References:
[1] Data science field guide - Booz Allen Hamilton
[2] Data Driven: https://www.oreilly.com/library/view/data-driven/9781491925454/