
Processes deployed inside and across an enterprise, when executed can leave an operational data footprint in the form of an event logs, which if analyzed can be a valuable source of insights to support the management and improvement of business processes. This Process execution data can transformed into an event log describing the sequence of activities that were performed, along with the resources involved in the execution. Each entry of the process execution log (also known as event logs) represents an event, which records the occurrence of an activity at a particular point in time and belongs to precisely one case (case represents a unique process instance). Events can be characterised by multiple descriptors (attributes), including an event (or activity name), a unique case identifier (e.g case ID), a timestamp and optionally details of resource responsible for executing the task of the process instance. An event refers to an activity (or a step) in the process and belongs to a process instance or a case.
Over the past two decades, problems such as automated process discovery, process conformance checking and process enhancement have been extensively studied. Automated Process discovery involves taking a process event log and extracting A process model which describes the behavior of a process accurately. "Any set of related activities that are executed in a repeatable manner and with a defined goal can be seen as process". Common to all process discovery approaches is the idea of extracting a process design from an event log which best represents the executions recorded in the process logs mined. Process mining techniques are primarily reliant on process logs, which don't always explicitly capture all the behaviour of past executed processes but certainly contain valuable insights.
For complex domains like healthcare, where improving clinical outcomes can directly impact the quality of life for patients. By considering a data-driven approach, process analysts can analyze event logs and provide support for improving process outcomes.
In a healthcare context the trajectory of a patient from arrival in the emergency ward to the admission to a hospital ward and up to the discharge can be seen as a process (sometimes also known as careflows). At a high-level, medical diagnosis process consists of gathering data, classifying and diagnosing a specific problem and suggesting a particular course of treatment. The notion of a clinical process (often also referred to as a careflow) underpins the practice of medicine. Clinical pathways are care plans that attempt to standardise clinical or medical treatment processes. The process data representing such pathways, is often recorded in hospital information systems and clinical data warehouses. i.e Often the execution of such a processes is supported by information systems. For example, the hospital may record medical information such as symptoms, the condition upon arrival of the patient, and the results of blood tests. Moreover also logistical information are recorded such as the movement of patients between wards and different types of discharge.
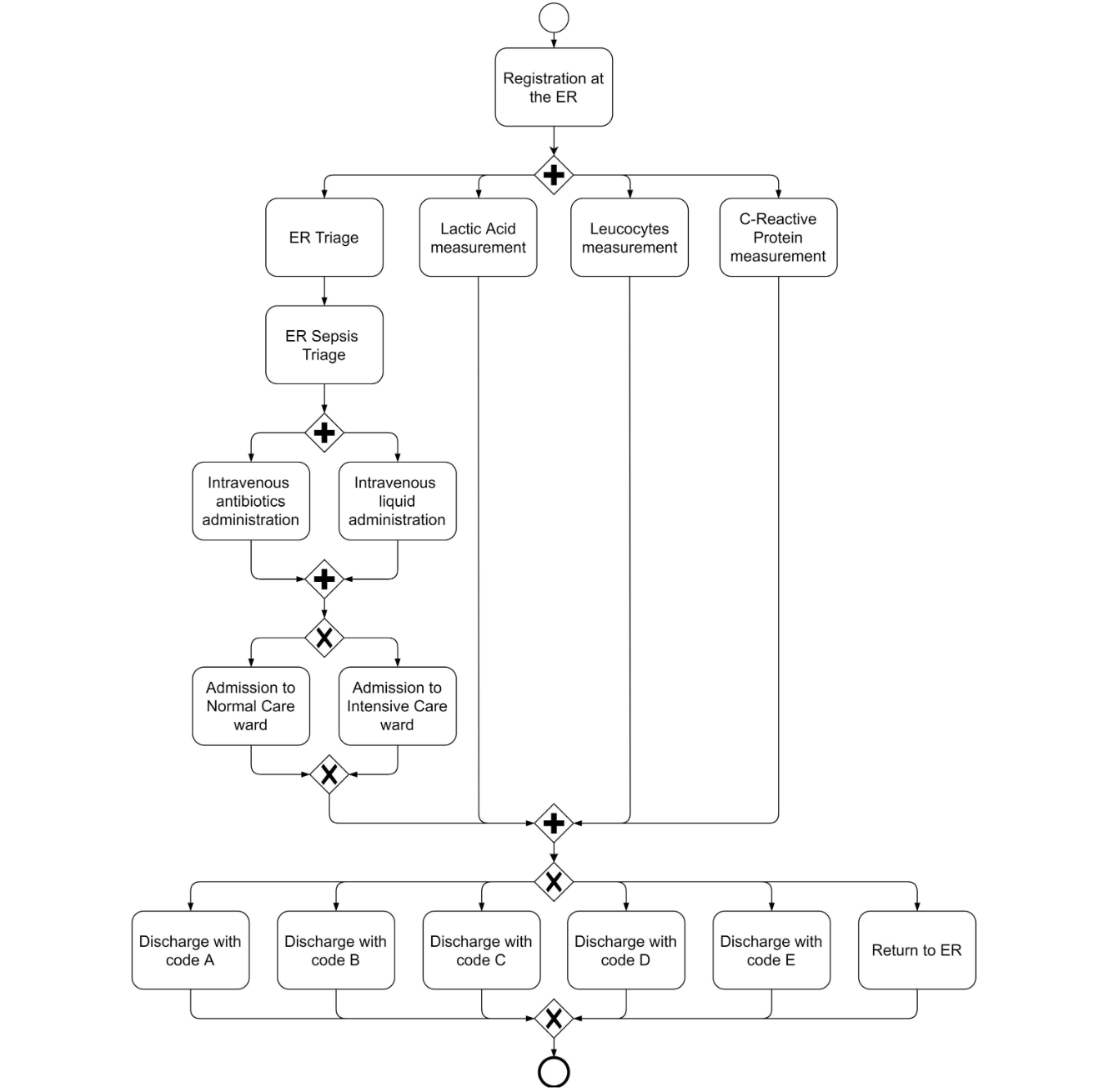
To illustrate the concept, let us consider an example of sepsis treatment careflow, where clinicians face complicated decision problems during the patient treatment process in an emergency room. In practice, sepsis treatment is highly knowledge-driven and consists of predictable and unpredictable elements. As the process evolves, knowledge workers (team of doctors) involved in the process make decisions based on clinical observations and patient data that is being constantly updated. Full process of management of the disease and associated decision making policy is fairly complicated where Treatment can include administration of antibiotics, source control, intravenous fluid therapy and organ system support with vasopressor drugs, mechanical ventilation, and renal replacement therapy as required [4].
There is a growing recognition of the potential benefits of applying Process mining in understanding and optimizing the clinical care pathways of the patient treatment process. The vast array of personalized processes that are recorded in process histories, coupled with contextual information about patient demographics, medical history and co-morbidities can form a rich data source for mining insights. Process mining techniques assist process analysts in understanding the impact and correlation of clinical activities of a given patient.
About the dataset:
We consider an event log, a real world example of sepsis treatment, representing treatment of 1050 patients over the course of 1.5 years, where events were recorded by the ERP (Enterprise Resource Planning) system of the hospital. There are about 1000 cases with total of 15,000 events that were recorded for 16 different activities. Here, we limit the complexity to keep the scope of our example manageable by focusing on a sub-group of patients and a subset of a mix of medical and logistical activities. Event log typical is a good starting point for describing the sequence of activities that were performed
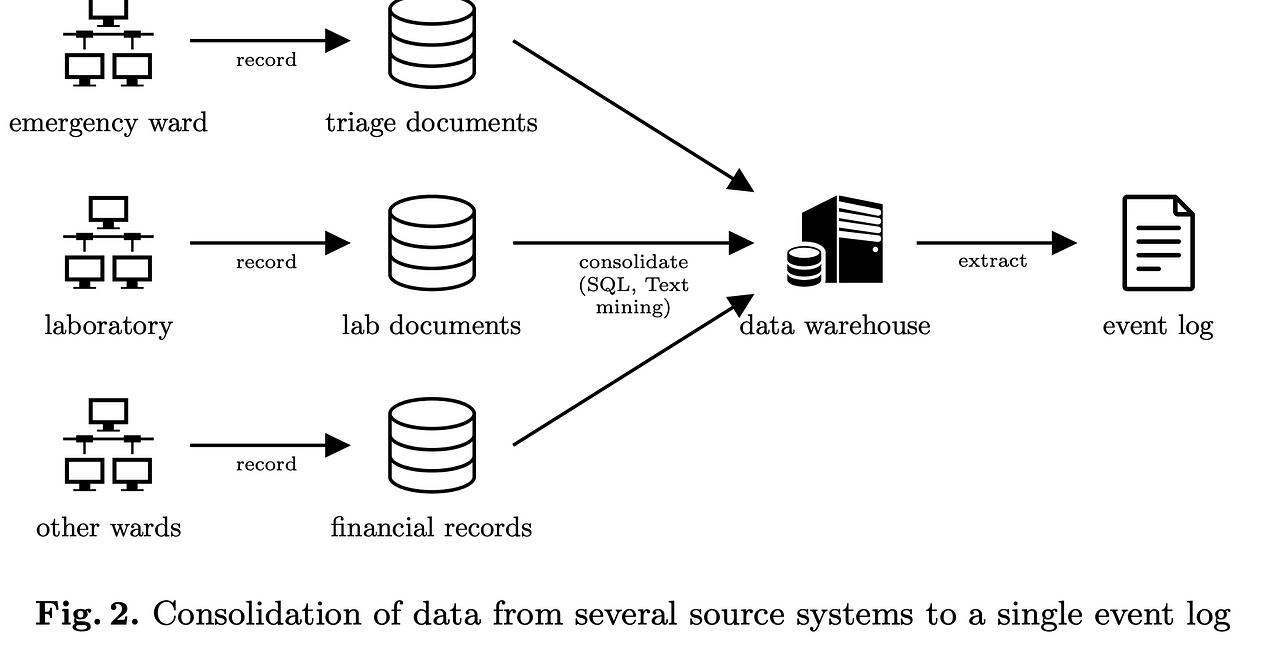
Moreover, 39 data attributes are recorded, e.g., the group responsible for the activity, the results of tests and information from checklists.
The event log contains events for 16 activities:
- 3 activities regarding the registration and triaging in the emergency ward;
- 3 activities regarding measurement of leukocytes, CRP, and lactic acid;
- 2 activities regarding admission or transfer to normal care or intensive care;
- 5 activities for variants of discharge from the hospital; and
- an activity concerned with returning patients at a later time
Extracted Process Model using Process Discovery Algorithm:
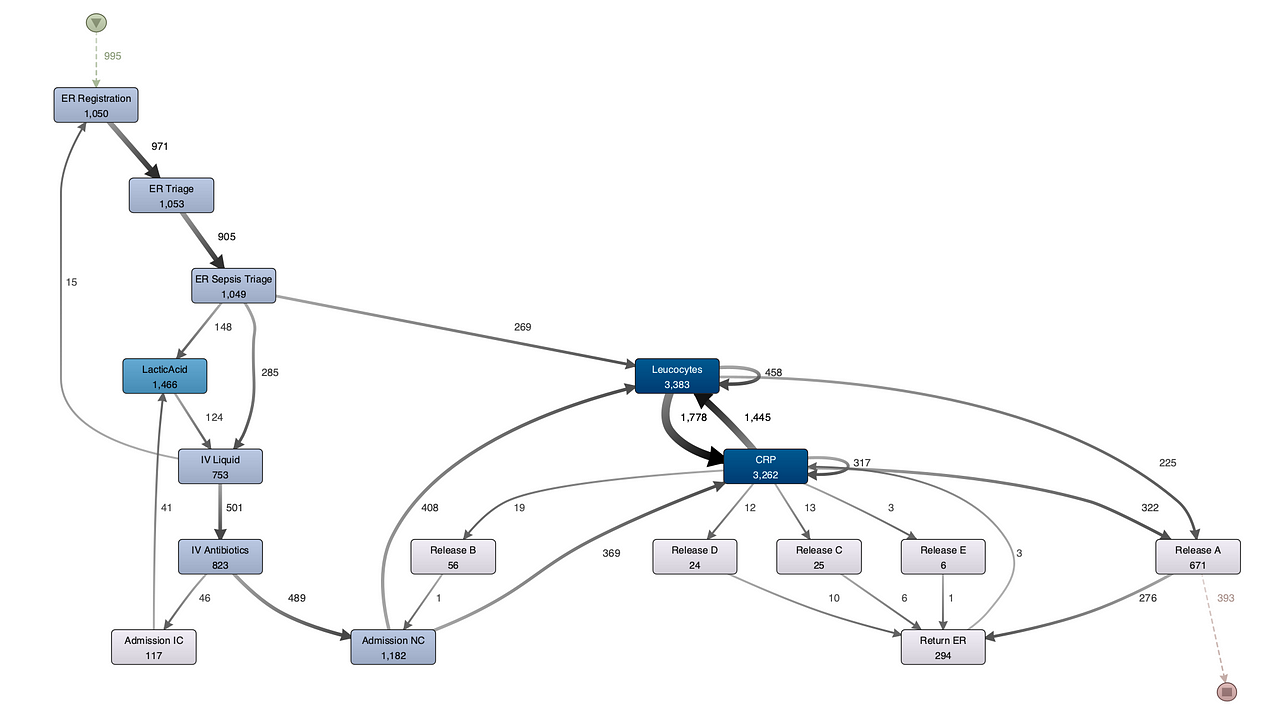
Process Re-Engineering with Process Mining:
Process mining has been used by healthcare providers to understand and optimize their care pathways of patients. We can extract the model from the event log using any of the available process mining tools. In this case we use a commerically tool called DISCO. The final process model shows 16 activities some of which are administrative (figure 3). As a first step towards process Improvement we can compare it to the model obtained by domain experts(medical professionals) working in emergency room using alignment-based conformance checking techniques to see how much of the on ground process matches the designed process. Moreover we can compare the extracted process to medical guidelines set by the medical commiunity using conformance checking techniques. e.g "Guidelines recommend to administer antibiotics within one hour". Note that it is challenging to extract actionable results in the first pass. This is due to several reasons. e.g data quality, selection of right abstraction. i.e The structural complexity, poor data quality and data incompleteness of available data is a major challenge during process discovery. Process mining algorithms can extract a process model as shown in Figure above. However due to data quality challenges, some of the behaviour cannot be accurately extracted using the process discovery algorithms, limiting the mined model's utility.
Outside of this example, We often observe that the dominant approach thus far in process mining is hermeneutic, where existing process analytics techniques are designed only to exploit available event logs. This leads to a scenario where the mining algorithms either produce large spaghetti-like models and are often susceptible to under-fitting or over-fitting of the available logs. For process analysts, this implies that they miss out on the opportunities for a complete understanding of the underlying processes and subsequently extracting higher-impact insights that might have been possible if the behaviour was completely captured and available for mining in the event logs.
What can be done to improve these process mining algorithms?
From a research perspective there is a lot of room for improvement in terms of how we approach the contruction of process discovery algorithms:
One thing we can do is to rule out infeasible possibilities (and combinations thereof) in dependency relations. For example we consider a rule-based reasoning approach where we apply automated symbolic learning to learn a model of logical formulae in the form of closed-path rules. Considering our sepsis example, these rules maybe be based on clinical guidelines developed by the medical community. In our sepsis example, the mined model incorrectly allows us to skip all activities between registration and discharge. A rule based on sepsis guidelines of the form For adults suspected of having sepsis, perform immediate sepsis screening test and admission during wait period can constraint the model and prevent this from happening. Overall, rules provide a layer of conceptual knowledge needed to analyse event logs and to infer agreement/disagreement between observed and true behaviour and reach conclusions about unrealistic possibilities. We note that true behaviour is not characterised by the designed process model rather by a set of all activities and their subsequent effects (post-conditions) that occurred on-ground during process execution.
Considering that the event log is the main input for process mining techniques, the quality of event logs is critical to the success of the process mining efforts. Process discovery from event logs remains a challenging problem as real-world process logs are often incomplete and don't explicitly capture all the behaviour of deployed processes. A domain expert might have a bunch of rules or facts about her domain, which can be useful for deducing more knowledge from the event log than what has been explicitly recorded. For example, reasoning on an available medical knowledge graph of infectious diseases along with patient data (like white blood cell count) will allow us to infer that patients who are compromised hosts(due immune problems) often also have gram-negative infections (caused by bugs like pesudo-monas). This kind of reasoning is challenging as; first, we require explicit specification of the conceptualisation of the given domain domain. Second reasoning mechanism must be robust to errors in the inputs to the system, to uncertainty in the knowledge, or to the gradual changes in the truth of various pieces of knowledge.
The problem of Knowledge reasoning over knowledge graphs for inferring new conclusions from existing data has been well studied. Using this existing work as our foundation, we could investigate the use of knowledge graphs for discovering missing events. Specifically, we can design process discovery algorithms that address the semantic incompleteness of an event trace, by inferring potential relations between entity pairs to automatically identify missing events, based on existing knowledge with the purpose of complementing the event log. For a partially complete trace $\sigma$,over a event log $L$, our machinery generates a set of candidate event traces $\sigma^{\prime}$ as a superset of $\sigma$ as output with the intent of improving the utility of mined models.
Variant Analysis: Process execution traces exhibit a high degree of variability, representing deviating behaviour, especially in flexible environments such as the healthcare domain. In a medical context, variations can occur due to patients' and clinicians' agency, scientific and clinical evidence, and personal or organizational capacity. For treating sepsis patients, deviations from clinical guidelines are fairly common in practice, to make allowance, for instance, for varying demographics (age, medical history) or for co-occurring conditions (sometimes, co-morbidities preclude the application of the standard protocol). Here, process owners are interested in identifying, quantifying, and reducing unwarranted clinical variation. To better understand the medical decisions underlying individual treatments, process analysts often carefully partition the data (care-flow instances) into cohorts based on the treatment provided by existing medical guidelines, patient profile (characterized by criteria like age group) and, the evidence base for prescribed treatment or patient's medical history. In our sepsis example, we can consider mapping each input trace to three major patient cohort classes namely, effective care, where trace variation implies the underuse of valid treatment or preference-sensitive care, where variation implies availability of multiple care options and patient exercising choice), and supply-sensitive care, where variation implies the volume of care provided is a reflection of organizational capacity rather than patient need. We could argue that process context mainly influences variant configuration and a wealth of relevant information can be found in non-process data (such as patient demographics and medical histories) which do not routinely appear in process logs, and which are not easily amenable to process mining.
[1] https://bmjopen.bmj.com/content/bmjopen/8/12/e019947.full.pdf
[2] http://ceur-ws.org/Vol-1859/bpmds-08-paper.pdf
[3] https://data.4tu.nl/repository/uuid:915d2bfb-7e84-49ad-a286-dc35f063a460
[4] Dellinger RP, Levy MM, Carlet JM, Bion J, Parker MM, Jaeschke R, Reinhart K, Angus DC, Brun-Buisson C, Beale R, Calandra T, Dhainaut JF, Gerlach H, Harvey M, Marini JJ, Marshall J, Ranieri M, Ramsay G, Sevransky J, Thompson BT, Townsend S, Vender JS, Zimmerman JL, Vincent JL (2008) Surviving sepsis campaign: international guidelines for management of severe sepsis and septic shock. Intensive Care Med 34:17–60
[5] Business Process Analytics: From Insights to Predictions by Marlon Dumas
Further readings:
- Effect of a Process Mining based Pre-processing Step in Prediction of the Critical Health Outcomes
- Process mining in oncology using the MIMIC-III dataset
- Process Mining of Disease Trajectories in MIMIC-III: A Case Study
- Process Mining tocess Mining to Discover and Preserve Infrequent Relations in equent Relations in Event Logs: An Application t ent Logs: An Application to Understand the Labor o Understand the Laboratory Test Ordering Process Using the MIMIC-III Dataset
- Process Mining of Disease Trajectories in MIMIC-III: A Case Study
- SUBPOPULATION PROCESS MINING IN HEALTH