
Online decision-making in the context of reinforcement learning involves a fundamental choice:
Exploitation: Make the best decision given current information
Exploration: Gather more information The best long-term strategy may involve short-term sacrifices Gather enough information to make the best overall decisions
Two potential definitions of exploration problem:
- How can an agent discover high-reward strategies that require a temporally extended sequence of complex behaviors that, individually, are not rewarding?
- How can an agent decide whether to attempt new behaviors (to discover ones with higher reward) or continue to do the best thing it knows so far? (from keynote ERL Workshop @ ICML 2019)
Techniques:
There are a variety of exploration techniques some more principled than others.
- Naive exploration — greedy methods
- Optimistic Initialisation — A very simple idea that usually works very well
- Optimism under uncertainty — prefer actions with uncertain values eg. UCB
- Probability matching — pick action with largest probability of being optimal eg. Thompson sampling
- Information state space — construct augmented MDP and solve it, hence directly incorporating the value of information
They are studied in the context of mulit-armed bandits (because we understand these settings well). I recommend watch this lecture for more details on fundamentals
let's now ask three basic questions from a research perspective :
1. How important is RL in exploration?
2. State of the art — Where do we stand ?
3. How do we assess exploration methods? and what would it mean to solve exploration?
1. How important is RL in exploration?
In this debate, There are two camps — one thinks exploration is super important and you have to get it right — its hard to build intelligent systems without learning and getting good data is important
the other camp thinks there will be so much data that getting the right data doesn’t matter — some exploration will be needed but the technique doesn’t matter.
we take the pendulum example where the task is to balance the pendulum in an upright position.
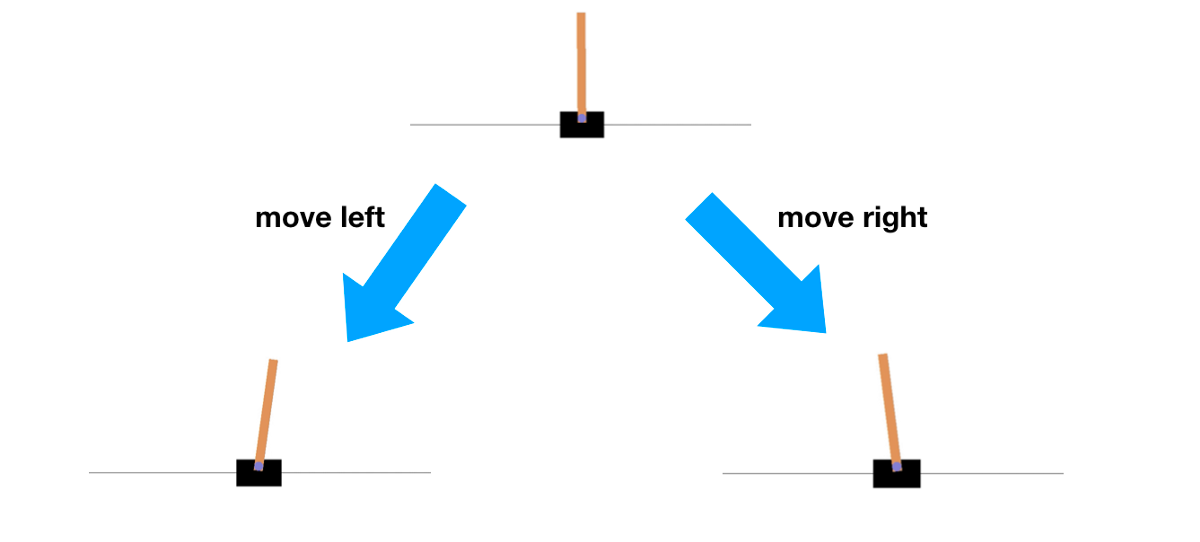
In this scenario, there is a small cost 0.1 for moving and reward when its upright and in the middle.
State of the art deep RL uses e-greedy exploration takes 1000 episodes and learns to do nothing, which means default exploration doesnt solve the problem. it requires planning in a certain sense or ‘deep exploration’ techniques, which usually help us gets there and learn to balance by the end of 1000 episodes.
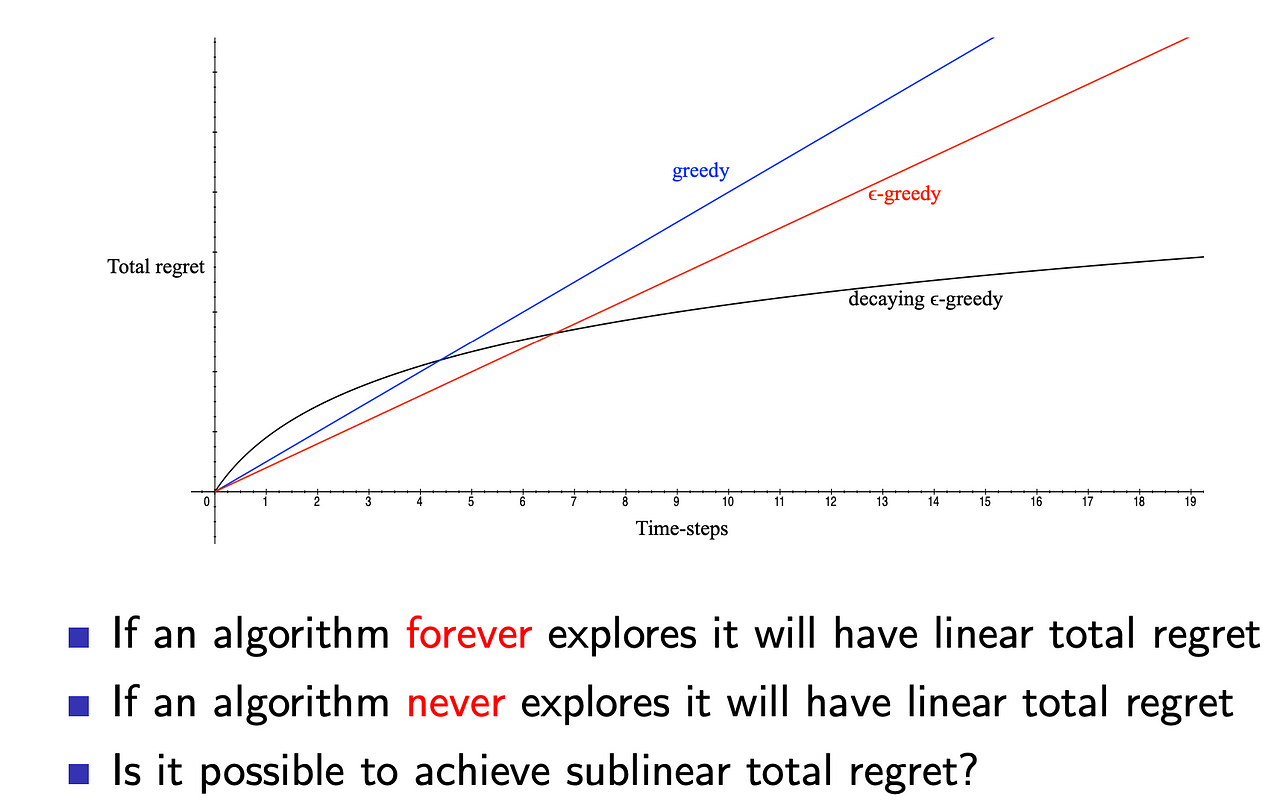
key lesson: exploration is key to learning quickly(off-policy) so its a core component but some problems can be solved without exploration. e.g driverless cars
What is the state of the art?
Exploration is not solved — we don’t have good exploration algorithms for the general RL problem — we need a principled/scaleable approach towards exploration.
Theoretical analysis/tractability becomes harder and harder as we go from top to bottom of the following list
- multi-armed bandits ( multi-armed bandits with independent arms is mostly solved )
- contextual bandits
- small, finite MDPs (exploration in tabular settings is well understood )
- large, infinite MDPs, continuous spaces

In many real applications such as education, health care, or robotics, asymptotic convergence rates are not a useful metric for comparing reinforcement learning algorithms. we can’t have millions of trails in the real world and we care about convergence and we care about quickly getting there. To achieve good real world performance, we want rapid convergence to good policies, which relies on good, strategic exploration.
other important open research questions:
- how do we formulate the exploration problem ?
- how do we explore at different time scales?
- safe exploration is an open problem
- mechanism is not clear — planning or optimism?
- generalisation (identify and group similar states) in exploration?
- how to incorporate prior knowledge?
How do we assess exploration methods? and what would it mean to solve exploration?
In General, we care about algorithms that have nice PAC bounds and regret but they have limitations where expected regret make sense — we should aim to design algorithms with low beysien regret. We know Bayes-optimal is the default way to asset these but that can be computationally intractable so literature on efficient exploration is all about trying to get good beyes regret but also maintain statistical efficiency
But how do we quantify notions of prior knowledge and generalisation? Which is why some experts in the area think its hard to pin down the definition of exploration. i.e when do we know when we will have but its not obvious
At the end of the day, we want intelligent directed exploration which means behaviour should be that of learning to explore . i.e gets better at exploring and there exists a Life long — ciricula of improving.
Scaling RL (taken from [1] and [2]):
Real systems, where data collection is costly or constrained by the physical context, call for a focus on statistical efficiency. A key driver of statistical efficiency is how the agent explores its environment.To date, RL’s potential has primarily been assessed through learning in simulated systems, where data generation is relatively unconstrained and algorithms are routinely trained over millions to trillions of episodes. Real systems, where data collection is costly or constrained by the physical context, call for a focus on statistical efficiency. A key driver of statistical efficiency is how the agent explores its environment. The design of reinforcement learning algorithms that efficiently explore intractably large state spaces remains an important challenge. Though a substantial body of work addresses efficient exploration, most of this focusses on tabular representations in which the number of parameters learned and the quantity of data required scale with the number of states. The design and analysis of tabular algorithms has generated valuable insights, but the resultant algorithms are of little practical importance since, for practical problems the state space is typically enormous (due to the curse of dimensionality). Current literature on ‘efficient exploration’ broadly states that only agents that perform deep exploration can expect polynomial sample complexity in learning(By this we mean that the exploration method does not only consider immediate information gain but also the consequences of an action on future learning.) This literature has focused, for the most part, on bounding the scaling properties of particular algorithms in tabular MDPs through analysis. we need to complement this understanding through a series of behavioural experiments that highlight the need for efficient exploration. There is a need for algorithms that generalize across states while exploring intelligently to learn to make effective decisions within a reasonable time frame.
[1] arxiv.org/pdf/1908.03568.pdf
[2] Deep Exploration via Randomized Value Functions: stanford.edu/class/msande338/rvf.pdf