
Language has historically been difficult for computers to ‘understand’. In NLP self-supervised learning, allows us to train models with a huge amount of unlabelled training data i.e., millions of sentences from the Internet (e.g. ), which saves a lot of time for labeling data. Pre-training and Fine-tuning have been sucessfully in both NLP and computer vision. The pretrain-fine tune paradigm is an instance of what is called transfer learning in machine learning: the method of acquiring knowledge transfer learning from one task or domain, and then applying it (transferring it) to solve a new task.
Pre-training: Pre-training refers to training a model to perform some task and then using the learned parameters as an initialization to learn a related Task. Pre-training on a dataset without using labels has been exceptionally effective at building strong representations of languages that work across a wider variety of downstream tasks. A model that has for example learned to predict the next word in a sentence will have learned something general about human langauge patterns. We would expect it to have a good initialisation for related tasks like translation or question answering.
In modern NLP, all (or almost all) parameters in NLP networks are initialized via pre-training. Pre-training methods hide parts of the input from the model, and train the model to reconstruct those parts. e.g Bert uses Masked Language Modeling objective where the model is trained to guess the missing information from an input. The pre-trained language models are useful in their ability to extract generalizations from large amounts of text—generalizations that are then applied for myriad of down-stream tasks/applications. This process overall gives the model a general understanding of the language semantics and a knowledge-base useful for reasoning.
Fine-tuning is the process of taking the pre-trained models, and further training the model to improve performance on a specific downstream task like 'named entity tagging' or 'question answering'. The intuition is that in the pre-training phase, model learns general properties about language, and can be then fine-tuned to solve supervised tasks like 'question answering'. i.e The language model, instantiates a rich representations of word meaning, that then enables the model to more easily learn (‘be fine-tuned to’) the requirements of a downstream language understanding task. During fine-tuning we can use small amounts of human-annotated data suitable for the task of interest. i.e The fine-tuning process consists of using labeled data related to the task at hand and train these additional task-specific parameters. Fine-tuning models can lead to new state-of-the-art performance for that particular task. Currently there are thousands of open-source and free, pre-trained models available which allow us to focus our efforts on fine-tuning to customize the model’s performance to a given NLP task.
Example: Using BERT's Language understanding capability for improving search:
The neural architecture influences the type of pretraining, and natural use cases. Bert for example, developed in 2018 by researchers at Google AI Language and serves as a swiss army knife solution to 11+ of the most common language tasks, such as sentiment analysis and named entity recognition. BERT was specifically trained on Wikipedia (~2.5B words) and Google’s BooksCorpus (~800M words). These large informational datasets contribute to BERT’s deep knowledge not only of the English language but also of our world! BERT’s training was made possible due to the novel Transformer architecture that process words in relation to all the other words in a sentence, rather than one-by-one in order. Transformers work by leveraging attention, and are uniquely suited for unsupervised learning because they can efficiently process millions of data points. From Information retrieval perspective, BERT helps Google better surface (English) results for nearly all searches since November of 2020. Here’s an example of how BERT helps Google better understand specific searches like:
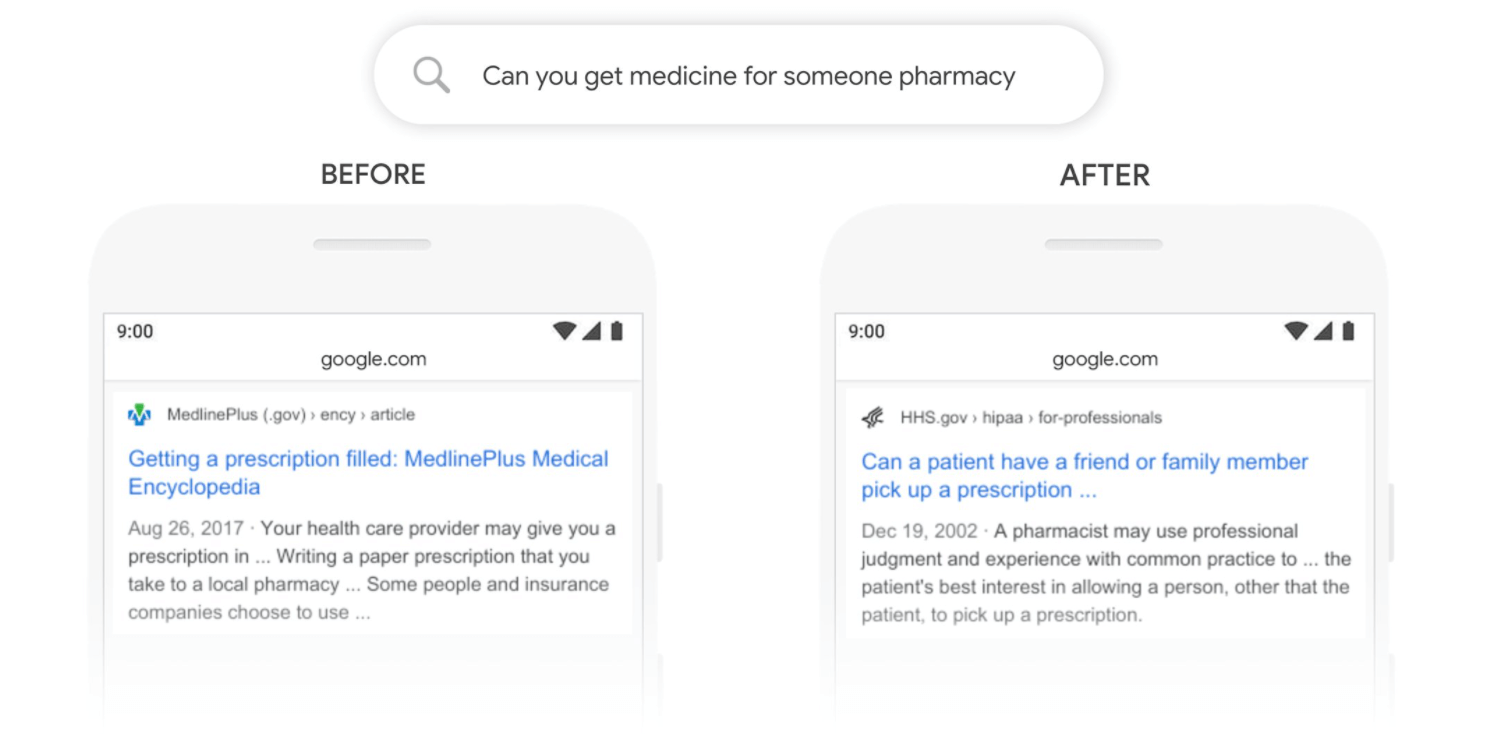
Pre-BERT Google surfaced information about getting a prescription filled.
Post-BERT Google understands that “for someone” relates to picking up a prescription for someone else and the search results now help to answer that.
News Article Summarization Case Study:
Summarization is the task of producing a shorter version of a document while preserving its important information. Summarization can be:
- Extractive: extract the most relevant information from a document.
- Abstractive: generate new text that captures the most relevant information.
Let's take a look at some general steps needed to deliver this functionality from an engineering perspective.
Data Collection Protocol:
We need to implement a data collection strategy that gives us the initial training data and overtime helps us build a data flywheel where we continusly adds to the initial training data for continuous improvement. To prepare a corpus geared towards news article summarization, we have the option of manually constructing a dataset by using human annotators where we ask experts to summarize the articles written by writers. Alternatively we need to look for internet sources. e.g this dataset https://huggingface.co/datasets/newsroom contains 1.3 million articles and summaries written by authors and editors in the newsrooms of 38 major publications.
Another options and possibly requiring more work is to scrap summaries from esspresso app summarizes the full length economist articles on daily basis and is a rich source of historical data that can be combied with original articles to create a labelled training dataset.
Lastly, one hack i can think of is to use news articles titles as their summaries and train the model to learn mapping from articles to titles as target summaries.
Following JSON format might be resonable for our purposes.
{
'summary': summary of article
'text': main content of article goes here
'title'(optional): title of news article
}Tools/Libraries:
Next, I will see which NLP libraries offer out of the box functionality for the task of summiarzation and provide production-grade, scalable and trainable implementations of deep learning models along with transfer learning capabilities. Since summarization is a popular NLP task, many libraries offer this functioanlity. We will consider hugging face and spark NLP as two promising candidates as both provide implementation of state of the art models and allow Industrial Grade NLP functionality. Spark NLP is a Natural Language Understanding Library built on top of Apache Spark, leveranging Spark MLLib pipelines, that allows us to run NLP models at scale. Hugging Face provides pre-trained models which are available in the open source and are free to use. Databricks is a great platform for running Hugging Face Transformers and Spark NLP and has good integration with major cloud platforms such as AWS, Azure and Google Cloud.
Using pre-trained models
Transformer models can be used to condense long documents into summaries. Training large models can be constly, therefore, We will rely on pre-trained T5, or Text-to-Text Transfer Transformer, which is a Transformer based architecture. T5 is trained with MLM (Masked Language Model) approach. The MLM is a fill-in-the-blank task, where the model masks part of the input text and tries to predict what that masked word should be. Every task – including translation, question answering, and classification – is cast as feeding the model text as input and training it to generate some target text. This allows for the use of the same model, loss function, hyperparameters, etc. across a diverse set of tasks.
Data Pre-Processing:
This step typically involves cleaning the data, tokeniztion and converting it into a tensors format where it can pass it to the model.
The pre-processing function we would want to create needs to perform following steps:
- Prefix the input with a prompt so T5 knows this is a summarization task.
- Use the keyword
text_targetargument when tokenizing labels. - Truncate sequences to be no longer than the maximum length set by the
max_lengthparameter where max_length = 128
Lastly, we will split the data to create validation and test datasets.
Fine-Tuning
Huggingface has made available a framework that aims to standardize the process of using and sharing models. This makes it easy to experiment with a variety of different models via an easy-to-use API. The transformers package is available for both Pytorch and Tensorflow. We will use this an existing language model and it be trained in a process called fine-tuning so it can solve the summarization task. Once that's done, we will use the fine-tuned model for inference. A rough tensorflow based solution (with key steps highlighted) would look like as follows [6].
#load T5 with TFAutoModelForSeq2SeqLM
from transformers import TFAutoModelForSeq2SeqLM
model = TFAutoModelForSeq2SeqLM.from_pretrained("t5-small")
#Encode the data in a way that t5 does
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("t5-small")
#split the data into train/test
news_article_summary_dataset = raw_dataset.train_test_split(test_size=0.2)
def preprocess_function(examples):
.
.
tokenized_news_article_summary_dataset = news_article_summary_dataset.map(preprocess_function, batched=True)
from transformers import DataCollatorForSeq2Seq
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model, return_tensors="tf")
from transformers import create_optimizer, AdamWeightDecay
optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
# Convert the dataset to the tf.data.Dataset format with prepare_tf_dataset():
tf_train_set = model.prepare_tf_dataset(
tokenized_news_article_summary_dataset["train"],
shuffle=True,
batch_size=16,
collate_fn=data_collator,
)
tf_test_set = model.prepare_tf_dataset(
tokenized_news_article_summary_dataset["test"],
shuffle=False,
batch_size=16,
collate_fn=data_collator,
)
#Configure the model for training with compile:
import tensorflow as tf
model.compile(optimizer=optimizer)
.
.
.
#ready to start training your model!
model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=callbacks)6. Evaluation:
- Automatic Evaluation: Including a metric during training is often helpful for evaluating your model’s performance. For example we can use Rouge Metric to get a sense of how well our model is performing.
- Human Evaluation: This may involve generating a bunch of summaries and asking human domain experts to rate them. Ultimately its the human evaluation that decides the best approach.
References: